SI1122469211

ARTIFICIAL INTELLIGENCE DALAM MEMBANDINGKAN 2 DOKUMEN UNTUK
MENGUKUR PROSENTASE TINGKAT KEMIRIPAN, STUDI KASUS: PADA TEKNIK INFORMATIKA DI

Disusun Oleh:
NIM |
: 1122469211
|
NAMA |
JURUSAN TEKNIK INFORMATIKA
KONSENTRASI SOFTWARE ENGINEERING
SEKOLAH TINGGI MANAJEMEN DAN ILMU KOMPUTER
TANGERANG
(2014)
SEKOLAH TINGGI MANAJEMEN DAN ILMU KOMPUTER
(STMIK) RAHARJA
LEMBAR PENGESAHAN SKRIPSI
ARTIFICIAL INTELLIGENCE DALAM MEMBANDINGKAN 2 DOKUMEN UNTUK MENGUKUR
PROSENTASE TINGKAT KEMIRIPAN, STUDI KASUS: PADA TEKNIK INFORMATIKA DI
Disusun Oleh:
NIM |
: 1122469211
|
Nama |
|
Jenjang Studi |
: Strata Satu
|
Jurusan |
: Teknik Informatika
|
Konsentrasi |
: Software Engineering
|
Disahkan Oleh:
Tangerang, Maret 2015
| Ketua |
Kepala Jurusan
| ||||
| STMIK RAHARJA |
Jurusan Teknik Informatika
| ||||
| (Ir. Untung Rahardja, M.T.I) |
(Junaidi, M.Kom)
| ||||
| NIP: 000594 |
NIP: 001405
|
SEKOLAH TINGGI MANAJEMEN DAN ILMU KOMPUTER
(STMIK) RAHARJA
LEMBAR PERSETUJUAN PEMBIMBING
ARTIFICIAL INTELLIGENCE DALAM MEMBANDINGKAN 2 DOKUMEN UNTUK MENGUKUR
PROSENTASE TINGKAT KEMIRIPAN, STUDI KASUS: PADA TEKNIK INFORMATIKA DI
Dibuat Oleh:
NIM |
: 1122469211
|
Nama |
Telah disetujui untuk dipertahankan dihadapan Tim Penguji Ujian Komprehensif
Jurusan Teknik Informatika
Konsentrasi Software Engineering
Disetujui Oleh:
Tangerang, Maret 2015
| Pembimbing I |
Pembimbing II
| ||
| (Junaidi, M.Kom) |
(Himawan, M.Kom)
| ||
| NID: 001405 |
NID: 12012
|
SEKOLAH TINGGI MANAJEMEN DAN ILMU KOMPUTER
(STMIK) RAHARJA
LEMBAR PERSETUJUAN DEWAN PENGUJI
ARTIFICIAL INTELLIGENCE DALAM MEMBANDINGKAN 2 DOKUMEN UNTUK MENGUKUR
PROSENTASE TINGKAT KEMIRIPAN, STUDI KASUS: PADA TEKNIK INFORMATIKA DI
Dibuat Oleh:
NIM |
: 1122469211
|
Nama |
Disetujui setelah berhasil dipertahankan dihadapan Tim Penguji Ujian
Komprehensif
Jurusan Teknik Informatika
Konsentrasi Software Engineering
Tahun Akademik 2013/2014
Disetujui Penguji:
Tangerang, Maret 2015
| Ketua Penguji |
Penguji I |
Penguji II
| ||
| (Ir. Untung Rahardja, M.T.I) |
(Meta Amalya Dewi, M.Kom) |
(Junaidi, M.Kom)
| ||
| NID: 99001 |
NID: 05062 |
NID: 05062
|
SEKOLAH TINGGI MANAJEMEN DAN ILMU KOMPUTER
(STMIK) RAHARJA
LEMBAR KEASLIAN SKRIPSI
ARTIFICIAL INTELLIGENCE DALAM MEMBANDINGKAN 2 DOKUMEN UNTUK MENGUKUR
PROSENTASE TINGKAT KEMIRIPAN,STUDI KASUS: PADA TEKNIK INFORMATIKA DI
Disusun Oleh:
NIM |
: 1122469211
|
Nama |
|
Jenjang Studi |
: Strata Satu
|
Jurusan |
: Teknik Informatika
|
Konsentrasi |
: Software Engineering
|
Menyatakan bahwa Skripsi ini merupakan karya tulis saya sendiri dan bukan merupakan tiruan, salinan, atau duplikat dari Skripsi yang telah dipergunakan untuk mendapatkan gelar Sarjana Komputer baik di lingkungan Perguruan Tinggi Raharja maupun di Perguruan Tinggi lain, serta belum pernah dipublikasikan.
Pernyataan ini dibuat dengan penuh kesadaran dan rasa tanggung jawab, serta bersedia menerima sanksi jika pernyataan diatas tidak benar.
Tangerang, Januari 2015
| NIM: 1122469211
|
)*Tandatangan dibubuhi materai 6.000;
ABSTRAKSI
Dalam dunia pendidikan terkadang terjadi praktik plagiatrisme atau penjiplakan hasil dari penelitian dan penulisan. Plagiatrisme atau yang sering di sebut dengan tindakan plagiat adalah penjiplakan atau pengambilan karangan, pendapat, dan sebagainya dari orang lain dan menjadikannya seolah karangan dan pendapat sendiri. Seperti mahasiswa yang sedang membuat penulisan ilmiah skripsi, terjadi tindakan plagiat dalam menyalin data (copy and paste). Adanya persamaan judul penulisan ilmiah skripsi antar mahasiswa membuat mahasiswa melakukan penyalinan data atau teks, sehingga memicu terjadinya penulisan ilmiah yang sama karena bersumber dari data yang sama, hal ini juga di dukung melimpahnya sumber informasi di internet. Untuk mendeteksi adanya tingkat kesamaan sumber data dokumen dan source code dapat dilakukan beberapa pendekatan yang sudah banyak di pakai. Pada penelitian ini akan di paparkan beberapa metode pendeteksi plagiat, sebagai solusi dari masalah tindakan plagiat yang telah terjadi selama ini. Dengan adanya beberapa metode pendekatan yang sudah banyak dipakai otomatis untuk mendeteksi tindakan plagiat, seperti Algoritma Winnowing, Algoritma Rabin-Karp dan algoritma levenshtein diharapkan dapat menghasilkan prosentase akurasi yang tinggi, hal ini dimungkinkan masing-masing pendekatan memiliki beberapa kelemahan dan kelebihan. Analisa model dapat menciptakan prosentase kemiripan yang tinggi dalam membandingkan dokumen karena antara pendekatan yang satu dengan yang lainnya bisa saling menutupi kekurangan.
Kata Kunci: plagiatrisme dokumen, winnowing, rabin-karp, levenshtein
ABSTRACT
In the world of education sometimes occurs practice plagiatrisme / plagiarism results of research and writing. Plagiatrisme or who is often called the act of plagiarism is plagiarism or making bouquets, opinions, etc. from others and make it as their own essays and opinion. Like the students who are making scientific writing thesis, an act of plagiarism in copying the data (copy and paste). The similarity between the title of scientific writing thesis students make students make copies of data or text, thus causing the same scientific writing as sourced from the same data, it also boosted the abundance of resources on the internet. To detect the level of similarity data source document and source code to do some of the approaches that have been widely in use. In this study will describe several methods of detecting plagiarism, as the solution of problems that plagiarism has occurred over the years. By there several methods that have been widely used approach automatically to detect plagiarism, such as the Winnowing algorithm, Rabin-Karp algorithm and algorithm levenshtein is expected to yield a high percentage of accuracy, it is possible each approach has some drawbacks and advantages. Analisa can create a model of a high percentage of similarity in comparing documents because of the approach one another with each other to cover the shortfall.
Keywords : plagiatrisme documents, Winnowing, Rabin-Karp, and levenshtein
Alhamdulillah Puji Syukur penulis panjatkan kehadirat Allah Swt, karena dengan rahmat dan hidayah-Nya penulis dapat menyelesaikan laporan Skripsi ini yang berjudul “Artificial Intelligence dalam membandingkan dokumen untuk mengukur prosentase kemiripan, study kasus: pada Teknik Informatika di Perguruan Tinggi Raharja”. Skripsi ini diambil sebagai salah satu syarat untuk kelulusan pada STMIK Raharja.
Tujuan dari pembuatan Skripsi ini adalah sebagai salah satu persyaratan dalam memperoleh gelar Sarjana Komputer (S.Kom) untuk jenjang S1 di Perguruan Tinggi Raharja, Cikokol Tangerang. Penulis berharap karya tulis ini dapat memberikan informasi yang bermanfaat dan tambahan pengetahuan bagi para pembaca umumnya serta mahasiswa pada khususnya. Dan semoga karya tulis ini dapat menjadi bahan perbandingan dalam periode selanjutnya, dan dapat menjadi suatu karya ilmiah yang baik.
Hati kecil ini pun menyadari bahwa tanpa bimbingan dan dorongan dari semua pihak penyusunan laporan Skripsi ini tidak akan berjalan sesuai dengan yang diharapkan. Oleh karena itu pada kesempatan yang singkat ini, izinkanlah penulis menyampaikan selaksa pujian dan terimakasih kepada:
- Bapak Ir. Untung Rahardja, M.T.I selaku Ketua STMIK Raharja.
- Bapak Sugeng Santoso, M.Kom, selaku Pembantu Ketua I STMIK Raharja.
- Bapak Junaidi, M.Kom selaku Kepala Jurusan Teknik Informatika, sekaligus Dosen pembimbing I dan Stackholder.
- Bapak Himawan, M.Kom Selaku Dosen Pembimbing II.
- Bapak dan Ibu Dosen Perguruan Tinggi Raharja yang telah memberikan ilmu pengetahuan kepada penulis.
- Kepada Ade Setiadi yang senantiasa membantu, memberi motivasi dan semangat agar laporan ini selesai dengan baik.
- Kepada Rivai Sungkowo sebagai mentor dan teman seperjuangan yang telah banyak membantu selama pembuatan aplikasi sistem.
- Kepada Teman-teman seperjuangan bersama menjalankan skripsi dan semua pihak yang mendukung yang tidak dapat disebutkan satu persatu.
Lebih khusus tak lupa penulis ucapkan kepada kedua Orang Tua dan keluarga, yang selalu memberi motivasi dan semangat, baik moril maupun materil dan do’a untuk keberhasilan penulis.
Penulis menyadari bahwa dalam penulisan Laporan Skripsi ini masih jauh dari sempurna. Oleh karena itu kritik dan saran yang membangun, penulis harapkan sebagai pemicu untuk dapat berkarya lebih baik lagi. Semoga Laporan Skripsi ini bermanfaat bagi pihak yang membutuhkan.
Akhir kata dari saya dan semua pihak yang telah membantu terwujudnya karya tulis ini, semoga Allah SWT melimpahkan rahmat dan hidayahnya Amin.
| Tangerang, Januari 2015 | |
| FIFIT ALFIAH | |
| NIM. 1122469211 |
Daftar isi
- 1 BAB I
- 2 BAB II
- 2.1 Konsep Dasar Algoritma
- 2.2 Konsep Dasar Kecerdasan Buatan
- 2.3 Konsep Dasar Flowchart
- 2.4 Konsep Dasar Dokumen Digital
- 2.5 Konsep Dasar Analisa SWOT
- 2.6 Konsep Dasar Database
- 2.7 Konsep Dasar Website
- 2.8 Konsep Dasar Normalisasi
- 2.9 Konsep Dasar Testing
- 2.10 Konsep Kesamaan Dokumen
- 2.11 Konsep Algoritma Winnowing
- 2.12 Konsep Algoritma Rabin-Karp
- 2.13 Konsep Algoritma Levenshtein
- 2.14 Konsep Dasar Literature Review
- 2.15 Literature Review
- 3 BAB III
- 3.1 Gambaran Gambaran Umum Perguruan Tinggi Raharja
- 3.2 Sejarah Singkat Perguruan Tinggi Raharja
- 3.3 Tata Laksana Sistem Yang Berjalan
- 3.4 Konfigurasi Sistem Yang Berjalan
- 3.5 Permasalahan Yang Dihadapi dan Alternatif PemecahanMasalah
- 3.6 User Requirement
- 4 BAB IV
- 5 BAB V
- 6 DAFTAR PUSTAKA
- 7 DAFTAR LAMPIRAN
DAFTAR TABEL
- Tabel 2.1 Tipe Data Pada MYSQL
- Tabel 2.2 Perbedaan Antara Penelitian Dasar,Terapan dan Evaluasi
- Tabel 3.1 Analisa SWOT
- Tabel 3.2 Elisitasi Tahap I
- Tabel 3.3 Elisitasi Tahap II
- Tabel 3.4 Elisitasi Tahap III
- Tabel 3.5 Final Draft Elisitasi
- Tabel 4.1 Tabel Unnormal
- Tabel 4.2 First Normal Form
- Tabel 4.3 Struktur Tabel informasi_dokumen
- Tabel 4.4 Struktur Tabel tingkat_kemiripan
- Tabel 4.5 Tabel Pengujian BlackBox
- Tabel 4.6 Schedule Implementasi
- Tabel 4.7 Estimasi Biaya
DAFTAR GAMBAR
- Gambar 1.1 Sistem Kerja dari Metode Pengujian Black Box
- Gambar 2.1 Pseucode Algoritma Rabin-Karp
- Gambar 2.2 Penerapan Konsep Kecerdasan Buatan di Komputer
- Gambar 2.3 Pohon Lingkup Kecerdasan Buatan & Aplikasi Utamanya
- Gambar 2.4 System Flowchart
- Gambar 2.5 Program Flowchart
- Gambar 2.6 Flow Direction Symbol
- Gambar 2.7 Input dan Output Symbol
- Gambar 2.8 Processing Symbol
- Gambar 2.9 Contoh file RTF menggunakan MS.Word
- Gambar 2.10 Contoh file Doc menggunakan MS.Word
- Gambar 2.11 Contoh file pdf menggunakan foxit reader
- Gambar 2.12 Ilustrasi Algoritma Sting Matching
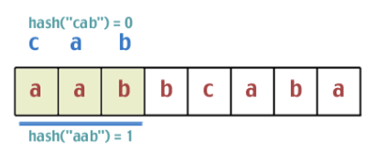
- Gambar 2.13 Fingerprint Awal
- Gambar 2.14 Menggeser fingerprint
- Gambar 2.15 Pembanding Kedua
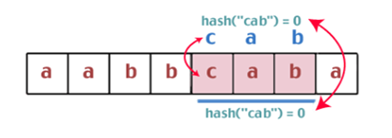
- Gambar 2.16 Pembanding Keempat (nilai hash sama)
- Gambar 2.17 Pembanding Kelima (string ditemukan)
- Gambar 2.18 Tahap dari Preprocessing
- Gambar 2.19 Proses Tokenizing
- Gambar 2.20 Proses Filtering
- Gambar 2.21 Proses Steming
- Gambar 2.22 Kompleksitas Rabin-Karp's O(nm), tapi hasil O(n+m)
- Gambar 2.23 Matriks yang sudah berisi nilai edit distance
- Gambar 3.1 Sertifikasi Akreditasi TI-S1 STMIK Raharja
- Gambar 3.2 Struktur Organisasi Perguruan Tinggi Raharja
- Gambar 3.3 Susunan Organisasi Divisi Akademik
- Gambar 3.4 Visi dan Misi STMIK Raharja
- Gambar 3.5 Visi dan Misi Program Studi Teknik Informatika
- Gambar 3.6 Flowchart analisa sistem yang berjalan
- Gambar 4.1 Second Normal Form (2NF)
- Gambar 4.2 Third Normal Form (2NF)
- Gambar 4.3 Flowchart Proses Sistem Artificial Intelligence
- Gambar 4.4 Flowchart PreprocessingUpload Dokumen Asli
- Gambar 4.5 Flowchart PreprocessingUpload Dokumen Uji
- Gambar 4.6 Flowchart Read Dokument Asli
- Gambar 4.7 Flowchart Read Dokument Uji
- Gambar 4.8 Flowchart Get Info Dokument Asli
- Gambar 4.9 Flowchart Get Info Dokument Uji
- Gambar 4.10 Flowchart Analyze result Paper
- Gambar 4.11 Flowchart Prosentase and Level Indikator
- Gambar 4.12 HIPO (Hierarchy Plus Input Process Output)
- Gambar 4.13 Prototype Tampilan Awal Program yaitu HOME
- Gambar 4.14 Prototype Halaman Scanning File
- Gambar 4.15 Prototype Halaman Report -> History
- Gambar 4.16 Prototype Halaman About Applicaton
- Gambar 4.17 Prototype Halaman About Me
DAFTAR SIMBOL
Daftar Simbol Flow Direction

Daftar Simbol Input Output

Daftar Simbol Processing

BAB I
Latar Belakang
Dalam dunia pendidikan terkadang sering terjadi praktik plagiarisme (penjiplakan) dalam penelitian dan penulisan ilmiah bagi mahasiswa. Penjiplakan atau plagiat menurut Permendiknas, (Pencegahan dan Penanggulangan Plagiat di Perguruan Tinggi, No 7, Pasal 1 ayat 1 2010) Plagiarisme atau yang sering di sebut dengan tindakan plagiat adalah penjiplakan atau pengambilan karangan, pendapat, dan sebagainya dari orang lain dan menjadikannya seolah karangan dan pendapat sendiri.
Penjiplakan di dunia pendidikan, (Universitas Pendidikan Indonesia 2012: 1-15) biasa terjadi jika seperti mahasiswa yang sedang membuat penulisan ilmiah terjadi tindakan plagiat dalam menyalin data (copy and paste) skripsi dengan banyaknya fasilitas internet, memudahkan para mahasiswa untuk melakukan tindakan plagiat.
Tindak plagiat kerap muncul dalam berbagai versi ada yang melakukan pengambilan keseluruhan dokumen karya orang lain dan menyebutnya karya sendiri, ada yang menulis kembali menerbitkannya, ada yang hanya menggunakan sebagian karya orang lain dengan mengabung-gabungkan beberapa karya orang lain.
Penulisan karya tulis ilmiah adalah kasus paling banyak terjadinya tindakan plagiat dalam dunia pendidikan yang dilakukan mahasiswa dan pengajar (Pikiran Rakyat, 2/3/212), karena teknologi yang menunjang dan adanya kemiripan judul penulisan ilmiah antar mahasiswa, sehingga membuat mahasiswa melakukan penyalinan teks atau data (copy and paste) pada penulisan ilmiah skripsi sehingga memungkinkan terjadinya penulisan ilmiah yang sama karena bersumber dari data yang sama dengan melimpahnya segala sumber informasi hanya dengan mengakses internet membuat semakin banyaknya jenis plagiat dalam segala bentuk.
Berbagai macam cara telah dilakukan oleh para peneliti untuk mengurangi tindakan plagiat. Untuk meminimalisasi praktik plagiarisme, diperlukan pendeteksian terhadap penulisan sebuah karya tulis. Oleh karena itu perlu dibuat sebuah algoritma dalam bentuk aplikasi yang dapat mendeteksi kemiripan sebuah dokumen dengan dokumen lainnya yang dijadikan sebagai pembanding. Berdasarkan latar belakang diatas, maka penulis mencoba untuk melakukan analisis dan kajian terhadap adanya tindakan plagiat pada dokumen penulisan ilmiah dengan judul "Artificial Intelligence dalam membandingkan dokumen untuk mengukur prosentase kemiripan, studi kasus: pada Teknik Informatika di Perguruan Tinggi Raharja".
Rumusan Masalah
Setiap penelitian dimulai dari rumusan masalah yang dilanjutkan dengan pemecahan masalah. Rumusan masalah berbeda dengan masalah. Masalah merupakan kesenjangan antara yang di harapkan dengan yang terjadi, maka rumusan masalah itu merupakan suatu pertanyaan yang akan dicarikan jawabannya melalui pengumpulan data. Masalah akan timbul apabila ada kesenjangan antara teori (what should be) dengan kenyataan yang dijumpai (what is).
Maka dari penjelasan rumusan masalah tersebut, dapat ditarik beberapa permasalahan sebagai berikut:
Bagaimana cara membandingkan dokumen untuk mengukur prosentase level indikator kemiripan pada penulisan ilmiah yang akan dilakukan oleh kalangan akademis pada Teknik Informatika di Perguruan Tinggi Raharja?
Apakah dengan hasil prosentase tingkat kemiripan bisa digunakan dengan optimal untuk menentukan seberapa besar kemiripan dokumen, sehingga dapat mengetahui status tingkat kemiripannya pada Teknik Informatika di Perguruan Tinggi Raharja?
Apakah menganalisa prosentase kemiripan sebuah penulisan ilmiah akan dapat meminimalkan tindakan plagiat baik di kalangan para akademisi dan mahasiswa/i yang ada di dalam Teknik Informatika di Perguruan Tinggi Raharja?
Ruang Lingkup Penelitian
Setiap penulis memiliki persepsi dan gagasan yang berbeda-beda terhadap suatu hal. Untuk itu perlu diberikan batasan untuk menghindari penafsiran yang keliru atas judul penelitian ini. Untuk menghindari kesalahpahaman dalam menginterpretasi, sekaligus memudahkan pembaca dalam memahami judul penelitian ini. adapun batasan masalah dalam penelitian ini adalah sebagai berikut:
Peneliti memfokuskan penelitian ini pada analisa sebuah sistem membandingkan 2 dokumen untuk mengukuran prosentase tingkat kemiripan penulisan ilmiah. Hal ini dimaksudkan agar peneliti dapat fokus dalam satu bagian. Sehingga data yang diperoleh memudahkan peneliti untuk menganalisis data.
Penelitian ini akan membandingkan sebuah kemiripan dokumen dan memunculkan analisa jumlah prosentase kemiripan dan kata yang memiliki kemiripannya.
Penelitian ini mampu menganalisa semua jenis dokumen yang terpenting sudah di convert dalam bentuk pdf, karena penelitian terfokus hanya file dokumen berjenis pdf yang bisa di upload dan dapat di analisa.
Tujuan dan Manfaat Penelitian
Tujuan Penelitian
Adapun tujuan dari penulisan ini adalah:
Meminimalkan atau mengurangi tindakan plagiat pada sebuah karya ilmiah yang dilakukan pada kalangan akademis pada Teknik Informatika di Perguruan Tinggi Raharja.
Melindungi Hak Cipta kepemilikan dari sebuah dokumen karya ilmiah yang dipublikasikan.
Membantu para dosen pengajar dan mahasiswa dalam hal pemeriksaan dokumen karya ilmiah pada Teknik Informatika di Perguruan Tinggi Raharja.
Manfaat Penelitian
Adapun manfaat dari penulisan ini adalah:
Dapat meminimalkan atau mengurangi tindakan plagiat pada sebuah karya ilmiah yang dilakukan pada kalangan akademis pada Teknik Informatika di Perguruan Tinggi Raharja.
Dapat melindungi Hak Cipta kepemilikan dari sebuah dokumen karya ilmiah yang dipublikasikan oleh kalangan akademis pada Teknik Informatika di Perguruan Tinggi Raharja.
Dapat membantu para dosen pengajar dan mahasiswa dalam hal pemeriksaan dokumen karya ilmiah pada Teknik Informatika di Perguruan Tinggi Raharja.
Metodelogi Penelitian
Metode penelitian merupakan suatu rangkaian cara atau kegiatan pelaksanaan penelitian yang didasari oleh asumsi-asumsi dasar, pandangan-pandangan filosofis dan ideologis, pertanyaan dan isu-isu yang dihadapi. Rancangan ini menggambarkan prosedur atau langkah-langkah yang harus ditempuh, waktu penelitian, sumber data dan kondisi arti apa data dikumpulkan dan dengan cara bagaimana data tersebut dihimpun dan diolah untuk digunakan dalam pembuatan laporan.
Metodelogi Pengumpulan Data
Metodelogi Pengamatan Langsung (Observasi)
Metodelogi Wawancara (Interview)
Metodelogi Studi Pustaka
Merupakan cara pengumpulan data dimana penulis diharuskan untuk terlibat langsung dalam pencarian datanya atau peninjauan secara cermat dan langsung di lokasi penelitian. Peneliti melakukan peninjauan atau pengamatan secara langsung kelapangan pada Jurusan Teknik Informatika di Perguruan Tinggi Raharja dengan cara mengumpulkan data, informasi, dan mempelajari sistem” yang ada sebelumnya. Adapun hasil yang didapat dari observasi selama 2 (dua) bulan adalah mengetahui sistem dari sistem yang ada, sehingga penulis dapat melaporkan kegiatan langsung pada apa yang pernah dilihat dan dipelajari sehingga dapat dituangkan dalam penulisan laporan ini.
Merupakan teknik pengumpulan data yang dilakukan melalui tatap muka dan tanya jawab langsung antara pengumpul data maupun peneliti terhadap nara sumber atau sumber data. Melakukan kegiatan tanya jawab dengan Ketua Jurusan Teknik Informatika Perguruan Tinggi Raharja yaitu Bapak Junaidi, M.Kom yang berperan sebagai stakeholder pada penelitian ini, guna memperoleh informasi agar data yang diperoleh lebih akurat. Dari hasil wawancara dengan stakeholder, stakeholder menginginkan sistem kecerdasan buatan yang mampu mengecek sebuah kemiripan dokumen.
Adalah segala upaya yang dilakukan oleh peneliti untuk memperoleh dan menghimpun segala informasi tertulis yang relevan dengan masalah yang diteliti. Informasi ini dapat diperoleh dari buku-buku, laporan penelitian, karangan ilmiah, tesis atau disertasi, serta melakukan searching pada internet menggunakan sumber yang dapat dipercaya. Dengan melakukan kajian bahan-bahan pustaka yang ada, penulis dapat memperoleh informasi secara sistematis kemudian menuangkannya dalam bentuk rangkuman yang utuh.
Metodelogi Analisa
Metodelogi analisa sistem yang digunakan Analisis SWOT. SWOT adalah sebuah metode prosedur analisis kondisi yang mengklarifikasi kondisi objek dalam empat kategori Strength (Kekuatan), Weakness (Kelemahan), Opportunity (Faktor Pendukung) and Threat (Faktor Penghambat atau Ancaman). Faktor analisa SWOT dibagi menjadi 2 faktor, yaitu faktor internal dan eksternal.
Metode Perancangan
Metodelogi Perancangan sistem yang akan digunakan adalah Flowchart, flowchart adalah bagan-bagan yang mempunyai arus yang menggambarkan langkah-langkah penyelesaian suatu masalah. Flowchart merupakan cara penyajian dari suatu algoritma karena merancang sistem yang akan berjalan sangat penting agar mampu membuat program yang tepat sesuai standar dalam industri untuk visualisasi, merancang dan mendokumentasikan sistem piranti lunak dan dalam hal pembuatan sistem ini peneliti menggunakan notepad++ sebagai penulisan listing program PHP dan MySQL sebagai database.
Metode Testing
Testing adalah proses eksekusi suatu program untuk menemukan kesalahan sebelum digunakan oleh pengguna akhir (end-user). Salah satu metode pengujian perangkat lunak adalah Black Box Testing.
Black-Box Testing merupakan pengujian yang berfokus pada spesifikasi fungsional dari perangkat lunak, tester dapat mendefinisikan kumpulan kondisi input dan melakukan pengetesan pada spesifikasi fungsional program.

Gambar 1.1. Sitem kerja dari metode pengujian Black Box
Sistematika Penulisan
Guna memahami lebih jelas laporan SKRIPSI ini, maka penulisan laporan penelitian dilakukan dengan cara mengelompokkan materi menjadi beberapa sub bab dengan sistematika penulisan sebagai berikut:
BAB I PENDAHULUAN
Bab ini menjelaskan tentang informasi umum yaitu latar belakang penelitian, perumusan masalah, ruang lingkup penelitian, tujuan dan manfaat penelitian, metode penelitian, dan sistematika penulisan.
BAB II LANDASAN TEORI
Bab ini berisikan teori yang diambil dari beberapa kutipan buku, yang berupa pengertian dan definisi. Bab ini juga menjelaskan mengenai Algoritma Rabin-Karp, Algoritma Winnowing, Algoritma Jaro-Winkler, metode Hashing, metode String Metric, metode fingerprinting, literature review dan definisi lainnya yang berkaitan dengan sistem yang dibahas.
BAB III ANALISA SISTEM YANG BERJALAN
Bab ini berisikan analisa organisasi pada Teknik Informatika di Perguruan Tinggi Raharja, analisa batasan sistem, analisa sistem berjalan, tata laksana sistem berjalan, permasalahan yang dihadapi dan konfigurasi sistem.
BAB IV RANCANGAN SISTEM YANG DIUSULKAN
Bab ini berisikan rancangan usulan sistem yang akan di buat, rancangan basis data, flowchart sistem yang di usulkan, rancangan program, rancangan prototype, konfigurasi sistem usulan, testing, evaluasi, dan implementasi.
BAB V PENUTUP
Bab ini berisi kesimpulan dan saran yang berkaitan dengan analisa dan optimalisasi sistem berdasarkan yang telah diuraikan pada bab-bab sebelumnya.
BAB II
Konsep Dasar Algoritma
Definisi Algoritma
Algoritma berasal dari kata “algoritma”, kata ini tidak muncul dalam kamus Webster pada tahun 1957. Menurut Rinaldi Munir dalam Andi Nugroho (2011:10)[1], Para ahli bahasa menemukan kata algorism berasal dari nama cendikiawan muslim yang terkenal yaitu Abu Ja’far Muhammad Ibnu Musa Al-Khuwarijmi (Al-Khuwarijmi dibaca oleh orang Barat menjadi algorism) dalam bukunya yang berjudul Kitab Aljabar Wal-muqabala, yang artinya “Buku Pemugaran dan Pengurangan” (The book of restoration and reduction). Dari judul buku itu kita memperoleh kata “aljabar” (algebra). Perubahan dari kata algorism menjadi algorithm muncul karena kata algorism sering dikelirukan dengan arithmetic sehingga akhiran –sm berubah menjadi –thm.
“Algoritma adalah urutan langkah-langkah logis penyelesaian masalah yang disusun secara sistematis dan logis”. Kata logis merupakan kata kunci dalam algoritma. Langkah-langkah dalam algoritma harus logis dan harus dapat ditentukan bernilai salah atau benar.
Menurut Thomas H. Cormen dalam Andi Nuhrogo (2011:10)[1], Algoritma adalah prosedur komputasi yang mengambil beberapa nilai atau kumpulan nilai sebagai input kemudian di proses sebagai output sehingga algoritma merupakan urutan langkah komputasi yang mengubah input menjadi output.
Menurut Donald E. Knuth dalam Rinaldi Munir dalam Andi Nugroho (2011:10)[1], algoritma dalam pengertian modern mempunyai kemiripan dengan istilah resep, proses, metode, teknik, prosedur, rutin. Algor itma adalah sekumpulan aturan-aturan berhingga yang memberikan sederetan operasi-operasi untuk menyelesaikan suatu jenis masalah yang khusus.
Jenis-jenis Algoritma
Algoritma adalah independen terhadap bahasa pemrograman tertentu, artinya algoritma yang telah dibuat tidak boleh hanya dapat diterapkan pada bahasa pemrograman tertentu. Penulisan algoritma tidak terikat pada suatu aturan tertentu, tetapi harus jelas maksudnya untuk tiap langkah algoritmanya. Namun pada dasarnya algoritma dibagi menjadi beberapa macam berdasarkan format penulisannya (Rana Rahma, 2013)[2], yaitu:
Deskriptif
Meminta input 3 bilangan dari user, misalkan bilangan a, b, dan c.
Apabila bilangan a lebih besar dari b maupun c, maka bilangan a merupakan bilangan terbesar.
Jika tidak (bilangan a tidak lebih besar dari b atau c) berarti bilangan a sudah pasti bukan bilangan terbesar. Kemungkinannya tinggal bilangan b atau c. Apabila bilangan b lebih besar dari c, maka b merupakan bilangan terbesar. Sebaliknya apabila bilangan b tidak lebih besar dari c, maka bilangan c merupakan yang terbesar.
- Pseudocode
Algoritma bertipe deskriptif maksudnya adalah algoritma yang ditulis dalam bahasa manusia sehari-hari (misalnya bahasa Indonesia atau bahasa Inggris) dan dalam bentuk kalimat. Setiap langkah algoritmanya diterangkan dalam satu atau beberapa kalimat.
Sebagai contoh misalnya algoritma menentukan bilangan terbesar dari 3 bilangan berikut ini:
Pseudo berarti imitasi dan code berarti kode yang dihubungkan dengan instruksi yang ditulis dalam bahasa komputer (kode bahasa pemrograman). Apabila diterjemahkan secara bebas, maka pseudocode berarti tiruan atau imitasi dari kode bahasa pemrograman. Pada dasarnya, pseudocode merupakan suatu bahasa yang memungkinkan programmer untuk berpikir terhadap permasalahan yang harus dipecahkan tanpa harus memikirkan syntax dari bahasa pemrograman yang tertentu. Tidak ada aturan penulisan syntax di dalam pseudocode. Jadi tujuan pseudocode digunakan untuk menggambarkan logika urut-urutan dari program tanpa memandang bagaimana bahasa pemrogramannya dan tujuan utama penggunaan pseudocode yaitu untuk mempermudah pengguna dalam pemahaman dibandingkan menggunakan bahasa pemrograman yang umum digunakan, terlebih aspeknya yang ringkas serta tidak bergantung pada suatu sistem tertentu merupakan prinsip utama dalam suatu algoritma.

Gambar 2.1. Pseucode Algoritma Rabin-Karp
Struktur Dasar Algoritma
Algoritma berisi langkah-langkah penyelesaian suatu masalah. Langkah-langkah tersebut dapat berupa runtunan aksi (sequence), pemilihan aksi (selection), pengulangan aksi (iteration) atau kombinasidari ketiganya. Jadi struktur dasar pembangunan algoritma ada tiga, yaitu:
-
Struktur Runtunan
Digunakan untuk program yang pernyataannya sequential atau urutan.
-
Struktur Pemilihan
Digunakan untuk program yang menggunakan pemilihan atau penyeleksian kondisi.
-
Struktur Pengulangan
Digunakan untuk program yang pernyataannya akan dieksekusi berulang-ulang.
Konsep Dasar Kecerdasan Buatan
Definisi Kecerdasan Buatan
Artificial Intelligence (AI) atau kecerdasan buatan merupakan cabang dari ilmu komputer yang konsen dengan pengautomatisasi tingkah laku cerdas.
Ada beberapa definisi kecerdasan buatan (Artificial Intellegence), antara lain:
Menurut Sri Kusumadewi, 2013.[3] Artificial Intellegence merupakan “salah satu bagian ilmu komputer yang membuat agar mesin (komputer) dapat melakukan pekerjaan seperti dan sebaik yang dilakukan oleh manusia”.
Menurut Anita Desiani dan Muhammad Arhami dalam Kusumadewi, 2013.[4] Artificial Intelligence adalah “Bagian dari komputer sehingga harus didasarkan pada Sound Theoretical (Teori Suara) dan prinsip–prinsip dibidangnya.
Prinsip–prinsip ini meliputi struktur data yang digunakan dalam representasi pengetahuan, algoritma yang diperlukan untuk mengaplikasikan pengetahuan tersebut, serta bahasa dan teknik pemrograman yang digunakan dalam mengimplementasikannya. Dari definisi diatas maka dapat ditarik kesimpulan bahwa kecerdasan buatan (Artificial Intellegence) adalah suatu ilmu yang mempelajari cara membuat komputer yang didalamnya terdapat pengetahuan-pengetahuan yang diperlukan untuk mengaplikasikannya, sehingga komputer ini dapat melakukan pekerjaan-pekerjaan yang dilakukan oleh manusia.
Konsep Kecerdasan Buatan
Untuk melakukan aplikasi kecerdasan buatan, maka ada dua bagian utama yang sangat dibutuhkan yaitu (Wuryandani, 2012)[5]:
Basis pengetahuan (knowledge base), berisi fakta-fakta, teori, pemikiran dan hubungan antara satu dengan lainnya.
Motor inferensi (inference engine), yaitu kemampuan menarik kesimpulan berdasarkan pengalaman.

Gambar 2.2. Penerapan Konsep Kecerdasan Buatan di Komputer
Ada beberapa konsep yang harus dipahami dalam kecerdasan buatan, diantaranya (Efrain Turban, 2010)[6]:
Turing Test – Metode Pengujian Kecerdasan.
Pemprosesan Simbolik
- Heuristic
- Penarikan Kesimpulan (Inferencing)
-
Pencocokan Pola (Pattern Matching)
Turing Test merupakan sebuah metode pengujian kecerdasan yang dibuat oleh Alan Turing. Dalam konsep ini, penanya (manusia) akan diminta untuk membedakan yang mana merupakan jawaban manusia dan mana yang merupakan jawaban komputer. Apabila tidak dapat membedakan, maka Turing berpendapat bahwa mesin tersebut dapat di asumsikan cerdas.
Komputer semula didesain untuk pemprosesan numerik, sedangkan manusia dalam berfikir dan menyelesaikan masalah lebih bersifat simbolik. Sifat penting dari AI adalah bagian dari ilmu komputer yang melakukan proses secara simbolik dan non algoritmik dalam menyelesaikan masalah.
Heuristic merupakan sustu strategi untuk melakukan proses pencarian (search) ruang problem secara selektif, yang memandu proses pencarian yang kita lakukan sepanjang jalur yang memiliki kemungkinan sukses paling besar.
AI mencoba membuat mesin memiliki kemampuan berfikir atau mempertimbangkan (reasoning). kemampuan berfikir (reasoning) termasuk didalamnya proses penarikan kesimpulan (inferencing) berdasarkan fakta- fakta dan aturan dengan menggunakan metode hueristik atau pencarian lainnya.
AI bekerja dengan metode pencocokan pola (Pattern Matching) yang berusaha untuk menjelaskan objek, kejadian (event) atau proses, dalam hubungan logik atau komputasional.
Lingkup Kecerdasan Buatan Pada Aplikasi Komersial
Adanya irisan penggunaan kecerdasan buatan di berbagai disiplin ilmu tersebut menyebabkan cukup rumitya untuk mengklasifikasikan kecerdasan buatan menurut disiplin ilmu yang menggunakannya. Untuk memudahkan hal tersebut, maka pengklasifikasian lingkup kecerdasan buatan didasarkan pada output yang diberikan yaitu aplikasi komersial (meskipun sebenarnya kecerdasan buatan itu sendiri bukan merupakan medan komersial). Lingkup utama dalam kecerdasan buatan adalah (Sumber: Diktat Mata Kuliah Kecerdasan Buatan, Ir. Balza Achmad, M.Sc.E. 2012)[7]:
Sistem Pakar (Expert System). Disini komputer digunakan sebagai sarana untuk menyimpan pengetahuan para pakar. Dengan demikian komputer akan memiliki keahlian untuk menyelesaikan permasalahan dengan meniru keahlian yang dimiliki oleh pakar.
Pengolahan Bahasa Alami (Natural Language Processing). Dengan pengolahan bahasa alami ini diharapkan user dapat berkomunikasi dengan komputer dengan menggunakan bahasa sehari-hari.
Pengenalan Ucapan (Speech Recognition). Melalui pengenalan ucapan diharapkan manusia dapat berkomunikasi dengan komputer dengan menggunakan suara.
Robotika & Sistem Sensor (Robotics & Sensory Systems).
Computer Vision, mencoba untuk dapat menginterpretasikan Gambar atau objek-objek tampak melalui komputer.
Intelligent Computer-Aided Instruction. Komputer dapat digunakan sebagai tutor yang dapat melatih dan mengajar.
Game Playing.

Gambar 2.3. Pohon Lingkup Kecerdasan Buatan dan Aplikasi Utamanya
Konsep Dasar Flowchart
Definisi Flowchart
Menurut Adelia (2011:116)[8], “Flowchart adalah penggambaran secara grafik dari langkah-langkah dan urut-urutan prosedur dari suatu program”. Flowchart menolong analyst dan programmer untuk memecahkan masalah kedalam segmen-segmen yang lebih kecil dan menolong dalam menganalisis alternatif-alternatif lain dalam pengoperasian. Flowchart biasanya mempermudah penyelesaian suatu masalah khususnya masalah yang perlu dipelajari dan dievaluasi lebih lanjut.
Menurut Sulindawati (2010:8)[9], “Flowchart adalah penggambaran secara grafik dari langkah-langkah dan urutan-urutan prosedur dari suatu program”. Flowchart menolong analis dan programmer untuk memecahkan masalah kedalam segmen-segmen yang lebih kecil dan menolong dalam menganalisis alternatif-alternatif lain dalam pengopersian.
Berdasarkan beberapa pendapat yang dikemukakan di atas dapat ditarik kesimpulan flowchart atau diagram alur adalah suatu alat yang banyak digunakan untuk membuat algoritma, yakni bagaimana rangkaian pelaksanaan suatu kegiatan. Suatu diagram alur memberikan gambaran dua dimensi berupa simbol-simbol grafis. Masing-masing simbol telah ditetapkan terlebih dahulu fungsi dan artinya.
Model Penulisan Flowchart
System Flowchart
- Program Flowchart

Gambar 2.4. System Flowchart
Conceptual flowchart, menggambarkan alur pemecahan masalah secara global.
Detail flowchart, menggambarkan alur pemecahan masalah secara rinci.

Simbol-simbol Flowchart
Simbol-simbol yang di pakai dalam flowchart dibagi menjadi 3 kelompok:[1]
- Flow direction symbols
Processing symbols
Input atau Output symbols
Digunakan untuk menghubungkan simbol satu dengan yang lain dan juga connecting line.
Menunjukan jenis operasi pengolahan dalam suatu proses atau prosedur.
Menunjukkan jenis peralatan yang digunakan sebagai media input atau output.

Gambar 2.6. Flow Direction Symbol

Gambar 2.7. Input dan Output Symbol

Gambar 2.8. Processing Symbol
Konsep Dasar Dokumen Digital
Definisi Dokumen Digital
Dokumen adalah sebuah tulisan yang memuat data dan informasi. Biasanya, dokumen ditulis di kertas dan informasinya ditulis memakai tinta baik memakai tangan atau memakai media elektronik (seperti printer).
Dokumen digital merupakan setiap informasi elektronik yang dibuat, diteruskan, dikirimkan, diterima, atau disimpan dalam bentuk analog, digital, elektromagnetik, optikal, atau sejenisnya, yang dapat dilihat, ditampilkan dan atau didengar melalui komputer atau sistem elektronik, termasuk tetapi tidak terbatas pada tulisan, suara atau gambar, peta, rancangan, foto atau sejenisnya, huruf, tanda, angka, kode akses, simbol atau perforasi yang memiliki makna atau arti atau dapat dipahami oleh orang yang mampu memahaminya. (Supriyono, 2013)[10].
Pengolahan Dokumen Digital
Dengan pemahaman bahwa dokumen elektronik adalah salah satu koleksi perpustakaan digital, maka pengertian perpustakaan digital dapat menjadi acuan pengelolaan dokumen elektronik. Secara ringkas dapat dikatakan perpustakaan digital tidak hanya menyediakan dokumen elektronik namun juga menyediakan akses ke sumber informasi lain yang tersedia secara terpasang. Istilah terpasang mengacu pada perangkat keras, perangkat lunak dan data yang terkait adanya, dan kegiatan yang dilakukan di dunia maya (cyberspace). Istilah ini populer menunjukkan “tempat” di mana manusia berinteraksi menggunakan jaringan komputer, yakni internet.
Sekurang-kurangnya terdapat lima aspek yang perlu diperhatikan dalam pengelolaan data elektronik, yaitu:
pembakuan format dan keamanan
pengindeksan dan pengabstrakan
penyediaan link ke sumber informasi lain
analisis akses dan sitiran
kesiapan pustakawan.
Format Dokumen Digital
Dokumen digital memiliki beberapa format sesuai dengan perangkat lunak pengolahan yang digunakan untuk menghasilkan dokumen digital tersebut. Adapun beberapa jenis format dokumen digital yang sering dijumpai pada komputer adalah DOC, RTF dan PDF.
RTF (Rich Text Format)
- DOC (document)
- PDF (Portable Document Format)
Rich Text Format (RTF) adalah sebuah format dokumen yang dibuat oleh Microsoft, yang dibuat berdasarkan spesifikasi Document Content Architecture (DCA) yang dibuat oleh IBM untuk System Network Architecture (SNA). Format dokumen ini, dapat digunakan untuk mentransfer dokumen teks terformat antar aplikasi, baik itu di dalam satu platform atau platform yang berbeda seperti IBM PC dan Macintosh. Meskipun termasuk ke dalam kelas dokumen teks terformat, format RTF ini tetap menggunakan standar pengcodean ANSI (American National Standards Institute) ASCII (American Standard Code for Information Interchange), PC-8, Macintosh, Unicode atau IBM PC Character Set untuk mengontrol representasi dan pemformatan dari sebuah dokumen, baik itu ketika ditampilkan di layar ataupun ketika dicetak di atas kertas. Meskipun hanya berisi teks biasa, format ini dapat mendukung grafik dan tabel dalam sebuah dokumen, meski jika dalam dokumen terdapat gambar, ukurannya jauh lebih besar jika dibandingkan dengan format biner seperti format dokumen biner semacam Microsoft Word (*.doc) atau StarOffice Writer (*.sxw).

Gambar 2.9. Contoh File RTF menggunakan MS. Word
DOC (document) merupakan jenis file untuk dokumen yang dibuat dengan perangkat lunak pengolah kata seperti Microsoft Word, Open Office Writer atau Abiword. Format file ini sangat populer dari dulu sampai sekarang dan sudah menjadi standard bagi format dokumen digital. Adapun contoh file DOC yang diolah menggunakan Microsoft Word.

Gambar 2.10. Contoh File Doc Menggunakan MS.Word
PDF (Portable Document Format) adalah sebuah format berkas yang dibuat oleh Adobe System untuk keperluan pertukaran dokumen digital. Format PDF digunakan untuk merepresentasikan dokumen dua dimensi yang meliputi teks, huruf, citra dan grafik vektor dua dimensi. Dokumen PDF juga mampu mendukung hyperlink, forms, javascript, dan berbagai kemampuan lain yang dapat didukung dengan melakukan penambahan plugin. Dokumen PDF versi 1.6 memiliki kemampuan untuk menampilkan grafik tiga dimensi interaktif. Format berkas PDF dapat dilengkapi dengan label (tag) XML, teks ekuivalen, perbesaran visual teks (magnifier), penambahan fasilitas audio atau suara, dsb.
Berkas PDF dapat disandikan sehingga untuk dapat membuka atau mengeditnya diperlukan kata kunci tertentu. Penyandian berkas PDF dilakukan dalam dua tingkat, berkas PDF juga dapat diberi pembatasan DRM untuk membatasi aktivitas penggandaan, penyuntingan, maupun pencetakan berkas tersebut.

Gambar 2.11. Contoh File Pdf Menggunakan Foxit Reader
Konsep Dasar Analisa SWOT
Definisi Analisa SWOT
Menurut Rangkuti (2011:199)[11], penelitian menentukan bahwa kinerja perusahaan dapat ditentukan oleh kombinasi faktor internal dan eksternal. Kedua faktor tersebut harus dipertimbangkan dalam analisis SWOT. SWOT adalah singkatan darilingkungan internal strengths dan weakness serta lingkungan eksternal opportunities dan threats yang dihadapi dunia bisnis. Analisa SWOT membandingkan antara faktor eksternal peluang (opportunities) dan ancaman (threats) dengan faktor internal kekuatan (strengths) dan kelemahan (weakness). Analisa ini terbagi atas empat komponen dasar yaitu:
Kuadran 1
Kuadran 2
Kuadran 3
Kuadran 4
Ini merupakan situasi yang sangat menguntungkan. Perusahaan tersebut memiliki peluang dan kekuatan sehingga dapat memanfaatkan peluang dan yang ada. Strategi yang harus ditetapkan dalam kondisi ini adalah mendukung kebijakan pertumbuhan yang agresif (Growth Oriented Strategy).
Meskipun menghadapi berbagai ancaman, perusahaan ini masih memiliki kekuatan dari segi internal. Strategi yang harus diterapkan adalah menggunakan kekuatan untuk memanfaatkan peluang jangka panjang dengan cara strategi diversifikasi (produk atau pasar).
Perusahaan menghadapi peluang pasar yang sangat besar, tetapi di lain pihak menghadapi beberapa kendala atau kelemahan internal. Kondisi bisnis pada kuadran 3 ini mirip dengan question mark pada BCG matriks. Fokus strategi perusahaan ini adalah meminimalkan masalah-masalah internal perusahaan sehingga dapat merebut peluang pasar yang lebih baik. Misalnya, Apple menggunakan strategi peninjauan kembali teknologi yang digunakan dengan cara menawarkan produk-produk baru dalam industri microcomputer.
Ini merupakan situasai yang sangat tidak menguntungkan, perusahaan tersebut menghadapi berbagai ancaman dan kelemahan internal.
Menurut Yusmini (2011:68)[12], "Analisis SWOT adalah suatu bentuk analisis dengan mengidentifikasi berbagai faktor secara sistematis terhadap kekuatan-kekuatan (Strengths) dan kelemahan-kelemahan (Weakness) suatu lembaga atau organisasi dan kesempatan-kesempatan (Oportunities) serta ancaman-ancaman (Threats) dari lingkungan untuk merumuskan strategi perusahaan. Analisa ini didasarkan pada logika yang dapat memaksimalkan kekuatan (Strengths) dan peluang (Opportunities), namun secara bersamaan dapat meminimalkan kelemahan (Weakness) dan ancaman (Threats)."
Berdasarkan beberapa pendapat yang dikemukakandiatas, maka dapat disimpulkan Analisis SWOT menggambarkan secara jelas bagaimana peluang dan ancaman yang dihadapi oleh perusahaan dapat disesuaikandengan kekuatan dan kelemahan yang dimiliki.
Tujuan Analisa SWOT
Menurut Rangkuti (2011:197)[11], tujuan analisa SWOT yaitu membandingkan antara faktor eksternal peluang dan ancaman dengan faktor internal kekuatan dan kelemahan sehingga dari analisis tersebut dapat diambil suatu keputusan strategis suatu organisasi.
Pendekatan Pemecahan Masalah
Menurut Rangkuti (2011:197)[11], tujuan analisa SWOT yaitu membandingkan antara faktor eksternal peluang dan ancaman dengan faktor internal kekuatan dan kelemahan sehingga dari analisis tersebut dapat diambil suatu keputusan strategis suatu organisasi.
Product: produk atau jasa yang ditawarkan kepada pasar untuk memenuhi keinginan dan kebutuhan konsumen.
Price: biaya yang harus dikeluarkan konsumen untuk memperoleh produk atau jasa yang ditawarkan.
Place: lokasi dimana produk atau jasa tersedia.
Promotion: aktivitas untuk mengkomunikasikan produk atau jasa yang ditawarkan.
People: orang yang berperan dalam pelayanan produk atau jasa.
Process: proses terjadinya kontak antara konsumen dengan pihak penyedia produk atau jasa.
Physical Evidence: bukti fisik yangmempengaruhi penilaian konsumen terhadap produk atau jasa.
Konsep Dasar Database
Definisi Database
Menurut Prasetio (2012:181)[13], database adalah sebuah struktur yang umumnya dikategorikan dalam 2 (dua) hal, sebuah database flat dan sebuah database relasional. Database relasional lebih disukai karena lebih masuk akal dibandungkan database flat.
Menurut Mustakini (2009:46)[14], database adalah kumpulan dari data yang saling berhubungan satu dengan yang lainnya, tersimpan di perangkat keras komputer dan digunakan perangkat lunak untuk memanipulasi.
Dari definisi ini, terdapat tiga hal yang berhubungan dengan database, yaitu sebagai berikut ini:
Data itu sendiri yang diorganisasikan dalam bentuk database.
Simpanan permanen (storage) untuk menyimpan database tersebut. Simpanan ini merupakan bagian dari teknologi perangkat keras yang digunakan di sistem informasi. Simpanan permanen yang umumnya digunakan berupa hard disk.
Perangkat lunak untuk memanipulasi database. Perangkat lunak ini dapat dibuat sendiri dengan menggunakan bahasa pemrograman komputer atau dibeli dalam bentuk suatu paket. Banyak paket perangkat lunak yang disediakan untuk memanipulasi database. Paket perangkat lunak ini disebut dengan DBMS (Database Management System).
Berdasarkan beberapa pendapat yang dikemukakan diatas dapat ditarik kesimpulan database adalah kumpulan informasi yang disimpan di dalam komputer secara sistematik sehingga dapat diperiksa menggunakan suatu program komputer untuk memperoleh informasi informasi dari basis data tersebut. Berdasarkan beberapa pendapat yang dikemukakan diatas dapat ditarik kesimpulan database adalah kumpulan informasi yang disimpan di dalam komputer secara sistematik sehingga dapat diperiksa menggunakan suatu program komputer untuk memperoleh informasi informasi dari basis data tersebut.
Jenis Database Yang Digunakan
- Web server
- XAMPP
Menurut Anhar (2010:4)[15], definisi web server adalah sebagai berikut: Web server adalah aplikasi yang berfungsi untuk melayani permintaan pemanggilan alamat dari pengguna melalui web browser, dimana web server mengirimkan kembali informasi yang diminta tersebut melalui HTTP (Hypertext Transfer Protocol) untuk ditampilkan ke layar monitor komputer kita. Agar kita dapat mengubah isi dari website yang dibuat, kita membutuhkan program PHP. Script-script PHP tersebut yang berfungsi membuat halaman website menjadi dinamis. Dinamis artinya pengunjung web dapat memberikan komentar saran atau masukan pada website kita. Website yang kita buat menjadi lebih hidup karena ada komunikasi antara pengunjung dan kita sebagai web masternya.
Menurut Oktavian (2010:11)[16], “Web Server adalah aplikasi yang berguna untuk menerima permintaan informasi dari pengguna melalui web browser, dan mengirimkan permintaan kembali informasi yang diminta melalui HTTP (HyperText Transfer Protocol). Biasanya web server diletakkan di komputer tertentu pada web hosting”.
Menurut Arief (2011:19)[17], “Web server adalah program aplikasi yang memiliki fungsi sebagai tempat menyimpan dokumen-dokumen web. Jadi semua dokumen web baik yang ditulis menggunakan client side scripting maupun server scripting tersimpan didalam direktori utama web server (document root)”.
Berdasarkan beberapa pendapat yang dikemukakan diatas, maka dapat disimpulkan web server merupakan sebuah perangkat lunak yang bertugas menerima permintaan client melalui port HTTP maupun HTTPS dan merubah isi yang ada ke dalam format HTML.
Menurut Madcoms (2010:341)[18], sekarang ini banyak paket software instalasi webserver yang disediakan secara gratis diantaranya menggunakan XAMPP. Dengan menggunakan paket software instalasi ini, maka sudah dapat melakukan beberapa instalasi software pendukung webserver, yaitu Apache, PHP, phpMyAdmin, dan database MySQL.
Menurut Wardana (2010:8)[19], “XAMPP adalah paket software yang didalamnya sudah terkandung Web Server Apache, database MySQL dan PHP Interpreter”.
Menurut Nugroho (2009:74)[20], XAMPP merupakan paket PHP yang berbasis Open Source yang dikembangkan oleh sebuah komunitas Open Source. Sebagai informasi, nama XAMPP diambil dari singkatan berikut:
X: Program ini dapat dijalankan di banyak sistem operasi.
A: Apache, merupakan aplikasi web server.
M: MySQL, merupakan vaplikasi database server.
P: PHP, bahasa pemrograman web.
P: Perl, bahasa pemrograman.
- PhpMyAdmin
- PHP
- Hanya dapat dijalankan menggunakan web server, misal: Apache.
- Kode PHP diletakkan dan dijalankan di web server.
- Kode PHP dapat digunakan untuk mengakses database, seperti: MySQL.
- Merupakan software yang berdifat open source.
- Gratis untuk didonwload dan digunakan.
- Memiliki sifat multipaltform, artinya dapat dijalankan menggunakan sistem operasi apapun, seperti: Linux, Unix, Windows, dan lain-lain.
- Tahun 1995 PHP pertama kali dibuat oleh Rasmus Lerdorf, yang diberi nama FI (Form Interpreted) dan digunakan untuk mengelola form dari web. Pada perkembangannya , kode tersebut dirilis ke umum sehingga mulai banyak dikembangkan oleh programmer di seluruh dunia.
- Tahun 1997 PHP 2.0 dirilis. Pada versi ini sudah terintegrasi dengan bahasa pemrograman C dan dilengkapi dengan modulnya sehingga kualitas kerja PHP meningkat secara signifikan. Pada tahun ini juga sebuah perusahaan yang bernama Zend merilis ulang PHP denganlebih bersih, baik, dan cepat.
- Tahun 1998 PHP 3.0 diluncurkan.
- Tahun 1999 PHP versi 4.0 dirilis. PHP versi ini paling banyak digunakan pada awal abad 21 karena sudah mampu membangun web komplek dengan stabilitas kecepatan yang tinggi.
- Tahun 2004 Zend merilis PHP 5.0. dalam versi ini, inti dari interpreter PHP mengalami perubahan besar. Versi ini juga memasukan model pemrograman berorientasi objek ke dalam PHP untuk menjawab perkembangan bahasa pemrograman ke arah paradigma berorientaso objek.
- Lalu versi 6 PHP sudah support untuk Unicode. Juga banyak fitur penting lainnya yang telah di tambah ke dalam PHP 6.Berdasarkan pendapat yang dikemukakan diatas dapat ditarik kesimpulan bahwa PHP merupakan bahasa script yang dapat ditanamkan atau disisipkan ke dalam HTML.
- MySQL
Berdasarkan beberapa pendapat yang dikemukakan di atas, maka dapat disimpulkan bahwa dengan menggunakan PhpMyAdmin, maka aplikasi ini dapat membantu Anda dalam menavigasi beberapa database, table, log, dan beberapa hal lainnya.
Menurut Madcoms (2010:367)[18], penyimpanan data yang fleksibel dan cepat aksesnya sangat dibutuhkan dalam sebuah website yang interaktif dan dinamis. Database sendiri berfungsi sebagai penampungan data yang anda input melalui form website. Selain itu dapat juga di balik dengan menampilkan data yang tersimpan dalam database ke dalam halaman website. Jenis database yang sangat popular dan digunakan pada banyak website di internet sebagai bank data adalah MySQL. MySQL menggunakan SQL dan bersifat gratis, selain itu MySQL dapat berjalan di berbagai platform, antara lain Linux, Windows, dan sebagainya.


Konsep Dasar Website
Definisi Website
Jenis-Jenis Website
- Web statis adalah web yang isinya atau content tidak berubah-ubah. Maksudnya adalah isi dari dokumen web tersebut tidak dapat diubah secara cepat dan mudah. Ini karena teknologi yang digunakan untuk membuat dokumen web ini tidak memungkinkan dilakukan perubahan isi atau data. Teknologi yang digunakan untuk web statis adalah jenis client side scripting seperti HTML, Cascading Style Sheet (CSS). Perubahan isi atau data halaman web statis hanya dapat dilakukan dengan cara mengubah langsung isinya pada file mentah web tersebut.
- Web dinamis adalah jenis wen yang content atau isinya dapat berubah-ubah setiap saat. Web yang banyak menampilkan animasi flash belum tentu termasuk web dinamis karena dinamis atau berubah-ubah isinya tidak sama dengan animasi. Untuk melakukan perubahan data, user cukup mengubahnya langsung secara online di internet melalui halaman control panel atau administrasi yang biasanya telah disediakan untuk user administrator sepanjang user tersebut memiliki hak akses yang sesuai.
Konsep Dasar Normalisasi
Definisi Normalisasi
- First Normal Form (INF)
- Menghilangkan data yang muncul secara berulang dalam satu tabel.
- Memuat tabel tersendiri untuk setiap kelompok data yang berhubungan.
- Tentukan PK untuk setiap kelompok data yang berhubungan.
- Second Normal Form (2NF)
- Membuat tabel tersendiri untuk sekelompok nilai yang berhubungan dengan sekelompok records.
- Hubungan tabel-tabel yang terbentuk dengan foriegn key.
- Third Normal Form (3NF)
Untuk menjadi 1NF suatu tabel harus memenuhi dua syarat. Syarat pertama tidak ada kelompok data atau field yang berulang. Syarat kedua harus ada primary key atau kunci unik, yaitu field yang membedakan satu baris dengan baris lain dalam satu tabel. Pada dasarnya semua tabel selama tidak ada kolom yang sama merupakan bentuk tabel 1NF. Jadi, langkah normalisasi menuju INF adalah:
Untuk menjadi 2NF suatu tabel harus berada dalam kondisi 1NF dan tidak memiliki partial dependencies. Partial dependencies adalah suatu kondisi jika atribut non kunci tergantung segaian tetapi bukan seluruhnya pada primary key. Langkah normalisasi dari 1NF menuju 2NF adalah:
Untuk menjadi 3NF suatu tabel harus berada dalam kondisi 2NF dan tidak memiliki transitive dependencies. Transitive dependencies adalah kondisi dengan adanya ketergantungan fungsional antara dua atau lebih atribut nonkunci.
Konsep Dasar Testing
Definisi Testing
- Verifikasi
- Validasi
- Failure
- Fault
- Error
- Incident
Acuan dan Pengukuran Testing
- Waktu
- Biaya
- Kinerja Testing
- Kerusakan
Tipe dan Teknik Testing
- White Box Testing
- Black Box Testing
- Anggota tim tester tidak harus dari seseorang yang memiliki kemampuan teknis di bidang pemrograman.
- Kesalahan dari perangkat lunak ataupun bug seringkali ditemukan oleh komponen tester yang berasal dari pengguna.
- Hasil dari blackbox testing dapat memperjelaskan kontradiksi ataupun kerancuan yang mungkin ditimbulkan dari eksekusi perangkat lunak.
- Proses testing dapat dilakukan lebih cepat dibandingankan white box testing.
- Equivalence Partitioning
- Boundary Value Analysis
- Cause Effect Graph
- Random Data Selection
- Feature Test
Konsep Kesamaan Dokumen
Definisi Plagiatrisme
- Data teks seperti essay, artikel, jurnal, penelitian dan sebagainya.
- Dokumen teks yang lebih terstruktur seperti bahasa pemrograman.
Tipe-tipe Plagiatrisme
- Word-for-word plagiarism Menyalin setiap kata secara langsung tanpa diubah sedikitpun.
- Plagirism of authorship Mengakui hasil karya orang lain sebagai hasil karya sendiri dengancara mencantumkan nama sendiri menggantikan nama pengarang yang sebenarnya.
- Plagiarism of ideas Mengakui hasil pemikiran atau ide orang lain.
- Plagiarism of sources Jika seorang penulis menggunakan kutipan dari penulis lainnya tanpa mencantumkan sumbernya.
Klasifikasi Pencocokan String
- Sebuah teks (text), yaitu sebuah (long) string yang panjangnya n karakter.
- Pattern, yaitu sebuah string dengan panjang m.

- Exact string matching, merupakan pencocokan string secara tepat dengan susunan karakter dalam string yang dicocokkan memiliki jumlah maupun urutan karakter dalam string yang sama. Contoh: kata step akan menunjukkan kecocokan hanya dengan kata step.
- Inexact string matching atau Fuzzy string matching, merupakan pencocokan string secara samar, maksudnya pencocokan string dimana string yang dicocokkan memiliki kemiripan dimana keduanya memiliki susunan karakter yang berbeda (mungkin jumlah atau urutannya) tetapi string-string tersebut memiliki kemiripan baik kemiripan tekstual atau penulisan (approximate string matching) atau kemiripan ucapan (phonetic string matching). Inexact string matching masih dapat dibagi lagi menjadi dua yaitu:
- Pencocokan string berdasarkan kemiripan penulisan (approximate string matching) merupakan pencocokan string dengan dasar kemiripan dari segi penulisannya (jumlah karakter, susunan karakter dalam dokumen). Tingkat kemiripan ditentukan dengan jauh tidaknya beda penulisan dua buah string yang dibandingkan tersebut dan nilai tingkat kemiripan ini ditentukan oleh programmer. Contoh: compuler dengan compiler, memiliki jumlah karakter yang sama tetapi ada dua karakter yang berbeda. Jika perbedaan dua karakter ini dapat ditoleransi sebagai sebuah kesalahan penulisan maka dua string tersebut dikatakan cocok.
- Pencocokan string berdasarkan kemiripan ucapan (phonetic string matching) merupakan pencocokan string dengan dasar kemiripan dari segi pengucapannya meskipun ada perbedaan penulisan dua string yang dibandingkan tersebut. Contoh step, dengan steppe, sttep, stepp, stepe. Exact string matching bermanfaat jika pengguna ingin mencari string dalam dokumen yang sama persis dengan string masukan. Tetapi jika pengguna menginginkan pencarian string yang mendekati dengan string masukan atau terjadi kesalahan penulisan string masukan maupun dokumen objek pencarian, maka inexact string matching yang bermanfaat.
Konsep Algoritma Winnowing
Definisi algoritma Winnowing
- Jika terdapat string yang sama yang panjangnya sama dengan panjang t, dimana t merupakan jaminan ambang nilai yang ditentukan, maka pencocokan terdeteksi.
- Tidak dapat mendeteksi beberapa pencocokan jika lebih pendek dari gangguan nilai ambang k.
- Penghapusan karakter-karakter yang tidak relevan (whitespace insensitivity).
- Pembentukan rangkaian gram dengan ukuran k.
- Penghitungan nilai hash.
- Membagi ke dalam window tertentu.
- Pemilihan beberapa nilai hash menjadi document fingerprinting.
Metode Dokumen Fingerprinting
- Asumsikan teks adalah string s yang panjangnya t.
- Hilangkan tanda baca dan spasi.
- Sebelum melakukan fungsi hash dengan menggunakan notasi k- gram. k-gram merupakan substring yang berdampingan dari panjang k. Membagi dokumen menjadi k- gram, dimana k merupakan parameter yang di pilih pengguna.
- Lakukan fungsi hash untuk setiap k-grams.
- Memilih beberapa hasil hash menjadi dokumen fingerprinting. Permasalahan yang muncul adalah bagaimana memilih fingerprint dari hasil hash. Terdapat beberapa pendekatan untuk menangani masalah tersebut.
Hashing
Metode Rolling Hash


Konsep Algoritma Rabin-Karp
Definisi ALgoritma Rabin-Karp
- Menghilangkan tanda baca dan mengubah ke teks sumber dan kata yang ingin dicari menjada kata-kata tanpa huruf kapital.
- Membagi teks ke dalam gram-gram yang ditentukan nilai k-gram nya.
- Mencari nilai hash dengan fungsi rolling hash dari tiap gram yang terbentuk.
- Mencari nilai hash yang sama antara 2 teks.
- Menentukan persamaan 2 buah teks dengan persamaan Dice's Similarity Coefficient.
prinsip Algoritma Rabin-Karp



Ekstraksi Dokumen

Folding and Tokenizing

Filtering

Steming

Kompleksitas Rabin-Karp

- Baik untuk plagiarisme, Karena dapat menangani beberapa pencocokan pola, Rabin-Karp dapat mendeteksi plagiarisme efisien
- Tidak lebih cepat dari pencocokan kekerasan dalam teori, dalam tujuan praktek TIK kompleksitas O (n + m).
- Dengan fungsi hashing baik itu Bisa Efektif cukup dan mudah untuk Melaksanakan.
- Ada banyak pencocokan string algoritma yang lebih cepat dari O itu (n + m).
- Ini Praktis lambat seperti pencocokan kekerasan dan membutuhkan ruang tambahan.
Konsep Algoritma Levenshtein
Definisi Algoritma Levenshtein


Konsep Metode Empiris Levenshtein Distance
- Operasi Pengubahan Karakter Operasi pengubahan karakter merupakan operasi menukar sebuah karakter dengan karakter lain contohnya penulis menuliskan string “yamg” menjadi “yang”. Dalam kasus ini karakter “m” diganti dengan huruf “n”.
- Operasi Penambahan Karakter Operasi penambahan karakter berarti menambahkan karakter ke dalam suatu string. Contohnya string “kepad” menjadi string “kepada”, dilakukan penambahan karakter “a” di akhir string. Penambahan karakter tidak hanya dilakukan di akhir kata, namun bisa ditambahkan diawal maupun disisipkan di tengah string.
- Operasi Penghapusan Karakter Operasi penghapusan karakter dilakukan untuk menghilangkan karakter dari suatu string. Contohnya string “barur” karakter terakhir dihilangkan sehingga menjadi string „baru‟. Pada operasi ini dilakukan penghapusan karakter “r”.


Konsep Dasar Literature Review
Definisi Literature Review
Tujuan Literature Review
- Untuk berbagi informasi dengan para pembaca mengenai hasil-hasil penelitian sebelumnya yang erat kaitannya dengan penelitian yang sedang kita laporkan.
- Untuk menghubungkan suatu penelitian ke dalam pembahasan yang lebih luas serta terus berlanjut sehingga dapat megisi kesenjangan-kesenjangan serta memperluas atau memberikan kontribusi terhadap penelitian-penelitian sebelumnya.
- Menyajikan suatu kerangka untuk menunjukan atau meyakinkan pentingnya penelitian yang dilakukan dan untuk membandingkan hasil atau temuan penelitian dengan temuan-temuam penelitian lain dengan topik serupa.
Jenis Penelitian
Jenis Penelitian Berdasarkan Pendekatan
- Asumsi tentang realitas
- Tujuan Penelitian
- Metode dan Proses Penelitian
- Kajian Khas
- Peranan Penelitian
- Pentingnya konteks dalam penelitian
Jenis Penelitian Berdasarkan Fungsinya


Jenis Penelitian Berdasarkan Tujuannya
- Penelitian Deskriptif (Descriptive Research)
- Penelitian Prediktif (Predictive Research)
- Penelitian Improtif (Improvetive Research)
- Penelitian Eksplanatif
- Penelitian Eksperimen
- Penelitian Ex Post Facto
- Penelitian Partisipatori (Parsticipatory Research)
- Penelitian Dan Pengembangan
Literature Review
- Mengidentifikasikan kesenjangan (identify gaps) dari penelitian ini.
- Menghindari pembuatan ulang (reinventing the wheel) sehingga menghemat waktu dan juga menghindari kesalahan-kesalahan yang pernah dilakukan oleh orang lain.
- Mengidentifikasikan metode yang pernah dilakukan dan yang relevan terhadap penelitian ini.
- Meneruskan apa yang penelitian sebelumnya telah dicapai sehingga dengan adanya studi pustaka ini, penelitian yang akan dilakukan dapat membangun diatas landasan (platform) dari pengetahuan atau ide yang sudah ada. serta mengetahui orang lain yang spesialisasi dan area penelitian yang sama dibidang ini.
- Penelitian ini di lakukan oleh Mudafiq Riyan Pratama, Eko Budi Cahyono dan Gita Indah Marthasari pada tahun 2012 dengan judul “Aplikasi Pendeteksi Duplikasi Dokumen Teks Bahasa Indonesia Menggunakan Algoritma Winnowing Dengan Metode K-Gram Dan Synonym Recognition” penilitian ini membahas tentang sistem deteksi duplikasi menggunakan algoritma yang outputnya menampilkan dalam bentuk seperangkat nilai-nilai hash sebagai fingerprinting dokumen yang diperoleh melalui metode k-gram. masukan dari Proses fingerprinting dokumen adalah file teks. Maka outputnya akan menjadi satu set nilai hash, yang disebut sidik jari. Fingerprint inilah yang akan menjadi dasar perbandingan antara file teks yang telah dimasukkan. keberadaan dari pengakuan konsep sinonim dimaksudkan untuk dapat mengenali kata-kata yang mengandung sinonim sebagai tindakan plagiarisme. Hasil dari penelitian sistem yang dibangun telah dapat mendeteksi duplikasi dengan pendekatan sinonim dengan perbedaan ± 0.82 % lebih besar menggunakan synonym recognition daripada tanpa synonym recognition. Pada dokumen yang dinyatakan telah terduplikasi, pendeteksian secara full dokumen (bab 1 sampai bab 5) dan parsial dokumen (bab 4 dan bab 5) akan mengalami peningkatan persentase ± 10 %. Sedangkan pada dokumen yang dinyatakan tidak terduplikasi, pendeteksian secara full dokumen maupun parsial dokumen akan secara otomatis mengalami penurunan persentase kemiripan ± 4.67 %. Dokumen dinyatakan terduplikasi jika persentase kemiripannya diatas 50 %.
- Penelitian ini di lakukan oleh Dewi Rokhmah Pyriana, Suprapto,ST.,MT.,Aswin Suharsono,ST.,MT. pada tahun 2012 dengan judul “Program Aplikasi Editor Kata Bahasa Indonesia Menggunakan Metode Approximate String Matching Dengan Algoritma Levenshtein Distance Berbasis Java” penilitian ini membahas tentang pembuatan program aplikasi editor kata bahasa indonesia yang menggunakan metode approximate string matching dengan algoritma levenshtein distance berbasis java yang bertujuan untuk membantu pekerjaan manusia dalam proses pengecekan kesalahan penulisan kata pada sebuah naskah dan mengubahnya menjadi kata yang benar, serta membantu mengetahui struktur kalimat tunggal dalam bahasa indonesia. Pada program ini, proses pengecekan ejaan kata Bahasa Indonesia dilakukan dengan proses tokenization dan pencocokan kata-kata baku yang ada di database dan memiliki tingkat kemiripan kata dengan menggunakan metode approximatestring matching dengan algoritma levenshtein distance ditentukan dengan cara mencari nilai jarak (edit distance) dari kata salah yang terdeteksi dengan semua kata baku yang ada di database. kata yang memiliki nilai jarak yang terkecil akan digunakan sebagai alternatif kata ganti untuk kata yang salah ejaannya. Hasil yang didapatnya struktur kalimat tunggal pada bahasa indonesia dapat diketahui dengan cara mendeteksi jenis kata yang terdapat dalam satu kalimat beserta letak katanya dan berdasarkan hasil pengujian, program editor kata bahasa indonesia untuk mengecek kebenaran ejaan kata memiliki validitas dan akurasi yang tinggi. pengujian menu cek editor kata memiliki akurasi 77,35% terhadap banyak variasi kata salah. pada menu cek struktur kalimat dengan 10 kalimat tunggal, akurasi yang dihasilkan 100%. Dan waktu yang dibutuhkan untuk eksekusi berbanding lurus dengan jumlah input kata. semakin banyak kata yang diinputkan, semakin banyak pula waktu yang dibutuhkan untuk eksekusi. sedangkan jumlah banyaknya kesalahan ejaan kata pada suatu teks tidak berpengaruh pada waktu eksekusi.
- Penelitian ini di lakukan oleh Eko Nugroho pada tahun 2012 dengan judul Skripsi “Perancangan Sistem Deteksi Plagiarisme Dokumen Teks Dengan Menggunakan Algoritma Rabin-Karp” penilitian ini membahas tentang pembuatan aplikasi dengan melakukan pencocokan string atau terms dan Algoritma yang digunakan dalam skripsi ini adalah Rabin-Karp. Algortima Rabin-Karp digunakan karena cocok untuk pola pencarian jamak (multiple pattern search). Pada penelitian ini dilakukan sedikit modifikasi untuk meningkatkan kinerja algoritma Rabin-Karp. Hasil dari penelitan ini adalah Algoritma Rabin-Karp biasa dan algoritma Rabin-Karp yang telah dimodifikasi mempunyai akurasi nilai similarity yang relatif sama. Tetapi algoritma Rabin-Karp yang dimodifikasi mempunyai rata-rata waktu proses yang lebih baik, terutama dokumen teks yang mempunyai size atau ukuran file yang besar dan Kgram yang semakin kecil menghasilkan akurasi nilai similarity yang lebih baik dibandingkan kgram yang lebih besar serta Persentase error yang dihasilkan kedua algoritma diatas relatif sama. Persentase error terkecil pada kgram=1. Persentase error berbanding lurus dengan perubahan jumlah kata. Semakin banyak perubahan pada teks tersebut maka persentase error yang dihasilkan semakin besar dan penggunaan stemming berpengaruh pada akurasi nilai similarity yang dihasilkan. Dengan menggunakan stemming menghasilkan nilai yang cenderung kurang baik dibandingkan tanpa menggunakan stemming. Tetapi pada kasus tertentu seperti pengubahan bentuk kalimat algoritma Rabin-Karp yang disisipi stemming menghasilkan akurasi nilai similarity yang lebih baik.
- Penelitian ini dilakukan oleh Fifit Alfiah, Junaidi pada tahun 2014 dengan judul “Collaborative Methods model dalam membandingkan dokumen untuk mengukur prosentase kemiripan”. Penelitian ini membahas tentang persentasi kemiripan atau kesamaan tingkat penulisan dalam analisa antar dokumen, untuk mengukur tingkat kesamaan atau kemiripan antara beberapa dokumen dilakukan pembandingan antara 2 dokumen untuk di analisa dalam segi penulisannya, dengan menggunakan beberapa metode dari algoritma yang berbeda agar dapat membuat sistem yang lebih akurat dan memberikan hasil kemiripan dengan sangat besar prosentasenya.
- Penelitian ini dilakukan oleh Anna Kurniawati, Sulistyo Puspitodjati dan Sazali Rahman pada tahun 2010 dengan judul “Implementasi Algoritma Jaro-Winkler Distance untuk Membandingkan Kesamaan Dokumen Berbahasa Indonesia” penelitian ini membahas tentang pembuatan aplikasi menghitung tingkat kesamaan dokumen berbasis web. Metode yang digunakan untuk menghitung tingkat kesamaan dokumen dengan menggunakan Algoritma jaro-winkler distance. Untuk dapat mengukur tingkat kesamaan dokumen dengan cepat, maka diperlukan alat bantu untuk dapat menghitung tingkat kesamaan antar dokumen. Hasil dari penelitian ini dalam ujicobanya aplikasi dapat berjalan dengan baik untuk memeriksa kemiripan dokumen yang identik atau sama seratus persen. Hal ini dikarenakan urutan kata-kata yang dibanding-kan sangat sesuai. Akan tetapi, saat memeriksa kemiripan dokumen dengan urutan yang berbeda aplikasi ini tidak mampu mendeteksi kemiripannya. Hal ini juga dikarenakan urutan kata yang telah berbeda pula.
- Penelitian ini dilakukan oleh Hari Bagus Firdaus pada tahun 2012 dengan judul “Deteksi Plagiat Dokumen Menggunakan Algoritma Rabin-Karp” penelitian ini membahas tentang bagaimana cara mengantisipasi tindakan plagiat, dibutuhkan suatu cara yang dapat menganalisis teknik-teknik plagiat yang dilakukan. Ada beberapa pendekatan yang bisa diambil, salah satunya dengan mempergunakan algoritma pencarian string Rabin-Karp. Penelitian ini hanya membahas secara skematis bagaimana algoritma Rabin-Karp bekerja dalam mendeteksi plagiat pada suatu dokumen, bukan implementasinya dalam sebuah program atau aplikasi.
BAB III
Gambaran Gambaran Umum Perguruan Tinggi Raharja
Sejarah Singkat Perguruan Tinggi Raharja
- Pada tanggal 08 Juli 2011 sesuai surat keputusan oleh Badan Akreditasi Nasional Perguruan Tinggi (BAN-PT) dengan Nomor 017/BAN-PT/Ak-VII/Dipl-III/XII/2007 yang berisi Badan Akreditasi Nasional Perguruan Tinggi menyatakan bahwa program studi Strata I Teknik Informatika di STMIK Raharja Informatika dengan terakreditasi B.

Struktur Organisasi


Wewenang dan Tanggung Jawab
- Presiden Direktur
- Menetapkan visi misi, tujuan dan strategi kampus.
- Menetapkan kebijakan umum berdasarkan kebijakan pemerintah dan arahan badan penyelenggara.
- Memimpin penyelenggaraan dan pembangunan pendidikan dan pengajaran, penelitian dan pengabdian kepada masyarakat, pembinaan aktivitas akademik baik pegawai penunjang, akademik maupun pegawai administrasi.
- Direktur
- Merupakan wakil presiden direktur.
- Ikut membantu presiden direktur dalam berbagai kegiatan.
- Penasehat Pimpinan
- Mengusulkan kepada Direktur atas prosedur pelaksanaan proses belajar mengajar.
- Mengusulkan kepada Direktur tentang kenaikan honor staff binaannya.
- Mengusulkan kepada Direktur tentang pengangkatan, pemberhentian staff binaannya.
- Memberikan kebijakan pelaksanaan layanan pada bidangnya.
- Mengusulkan kepada Direktur tentang unit layanan baru yang dibutuhkan.
- Memberikan sangsi kepada staff binaannya yang melanggar tata tertib karyawan.
- Mengusulkan kepada Direktur tentang pengangkatan dan pemberhentian dosen.
- Bertanggung jawab atas penyusunan JRS yang efektif dan efisien.
- Bertanggung jawab atas pengimplementasian pelaksanaan proses belajar mengajar.
- Bertanggung jawab atas kemajuan kualitas pelayanan Akademik yang berkesinambungan.
- Bertanggung jawab atas kelancaran proses belajar mengajar.
- Gugus Kendali Mutu
- Menjalankan program kebijaksanaan akademik.
- Mengawasi dan membina serta mengembangkan program studi sesuai kebijaksanaan yang telah digariskan.
- Membina dan mengembangkan kegiatan penelitian dan pengabdian pada masyarakat.
- Mengadakan afiliasi.
- Membina dan mengembangkan kelembagaan.
- Penasehat Umum Dan Staff Ahli
- Menyelenggarakan program kerja yang berpedoman pada visi, misi, fungsi dan tujuan pendirian Perguruan Tinggi Raharja.
- Menyelenggarakan kegiatan dan pengembangan pendidikan, penelitian serta pengabdian pada masyarakat.
- Menyelenggarakan kegiatan pengembangan administrasi.
- Menyelenggarakan kegiatan-kegiatan yang menunjang terwujudnya Tri Darma Perguruan Tinggi.
- Devisi Operasi
- Mengusulkan kepada Direktur atas prosedur pelaksanaan pelayanan proses belajar mengajar.
- Mengusulkan kepada Direktur tentang kenaikan honor.
- Mengusulkan kepada Direktur tentang kepangkatan, pemberhentian staf binaannya.
- Mengusulkan kepada Direktur tentang unit layanan baru yang dibutuhkan.
- Memberikan sanksi kepada staf binaannya yang melanggar tata tertib karyawan.
- Bertanggung jawab atas penyusunan kalender akademik tahunan.
- Bertanggung jawab atas pengimplementasian pelaksanaan pada bidangnya.
- Bertanggung jawab atas kemajuan kualitas pelayanan yang berkesinambungan pada bidangnya.
- Bertanggung jawab atas kelancaran proses belajar mengajar.
- Devisi Pemasaran
- Mengusulkan kepada Direktur atas prosedur pelaksanaan proses belajar mengajar.
- Mengusulkan kepada Direktur tentang kenaikan honor staf binaannya.
- Mengusulkan kepada Direktur tentang pengangkatan, pemberhentian staf binaannya.
- Memberikan kebijakan pelaksanaan layanan pada bidangnya.
- Mengusulkan kepada Direktur tentang unit layanan baru yang dibutuhkan.
- Memberikan sangsi kepada staf binaannya yang melanggar tata tertib karyawan
- Mengusulkan kepada Direktur tentang pengangkatan dan pemberhentian dosen.
- Bertanggung jawab atas penyusunan JRS yang efektif dan efisien.
- Bertanggung jawab atas pengimplementasian pelaksanaan proses belajar mengajar.
- Bertanggung jawab atas kemajuan kualitas pelayanan Akademik yang berkesinambungan.
- Bertanggung jawab atas kelancaran proses belajar mengajar.
- Devisi Keuangan Dan Pemasaran
- Mengusulkan kepada Direktur atas prosedur pembuatan budget pada setiap bagian dan pelaksanaan pemakaian dana.
- Mengusulkan kepada Direktur tentang kenaikan honor staf binaannya.
- Mengusulkan kepada Direktur tentang pengangkatan, pemberhentian staf binaannya.
- Memberikan kebijakan pelaksanaan layanan pada bidangnya.
- Mengusulkan kepada Direktur tentang unit layanan baru yang dibutuhkan.
- Memberikan sangsi kepada staf binaannya yang melanggar tata tertib karyawan
- Bertanggung jawab atas penyusunan budgetting pada setiap bagian.
- Bertanggung jawab atas tersedianya dana atas budget yang telah disetujui.
- Bertanggung jawab atas kemajuan kualitas pelayanan Akademik yang berkesinambungan.
- Bertanggung jawab atas kelancaran proses belajar mengajar.
- Ketua REC
- Ketua Jurusan
- Mengusulkan kepada Asisten Direktur Akademik tentang perubahan mata kuliah dan materi kuliah yang dianggap telah kadaluarsa bahkan perubahan Kurikulum Jurusan./li>
- Mengusulkan kepada Asisten Direktur Akademik tentang kenaikan honor dosen binaannya.
- Mengusulkan kepada Asisten Direktur Akademik tentang pengadaan seminar, pelatihan, penambahan kelas perkuliahan, pengangkatan dosen baru, pemberhentian dosen.
- Memberikan kebijakan administratif akademik seperti cuti kuliah, perpindahan jurusan, ujian susulan, pembukaan semester pendek.
- Mengusulkan kepada Asisten Direktur Akademik tentang pembukaan peminatan/konsentrasi baru dalam jurusannya.
- Memberikan sanksi akademik kepada mahasiswa yang melanggar tata tertib Perguruan Tinggi Raharja.
- Bertanggung jawab atas penyusunan dan pengimplementasian kurikulum, SAP dan Bahan Ajar.
- Bertanggung jawab atas monitoring kehadiran dosen dalam perkuliahan, jam konsultasi dan tugas-tugas yang disampaikan ke dosen.
- Bertanggung jawab atas terlaksananya penelitian dan pelaksanaan seminar.
- Bertanggung jawab atas pembinaan mahasiswa dan dosen binaannya.
- Bertanggung jawab atas prestasi Akademik mahasiswa.
- Bertanggung jawab atas peningkatan jumlah mahasiswa dalam jurusannnya.
Misi, Visi dan Tujuan

- Visi STMIK Raharja
- Misi STMIK Raharja
- Keunggulan Dalam Manajemen
- Keunggulan Dalam Pendidikan
- Keunggulan Dalam Penelitian
- Keunggulan Dalam Pengabdian Masyarakat
- Tujuan STMIK Raharja
- Memberikan jaminan manajemen mutu pelayanan yang prima bagi kepuasan stakeholders dengan mengacu kepada standar ISO 9001:2008.
- Memberikan jaminan kualitas pendidikan berkesinambungan untuk menghasilkan Pribadi Raharja yang mempunyai wawasan global, kompeten dalam bidang teknologi informasi dan mempunyai jiwa kemandirian serta kepemimpinan yang tangguh.
- Memberikan jaminan penelitian berkualitas dibidang Teknologi Informasi yang berkesinambungan dan berstandar internasional dengan memperhatikan kemajuan jaman dan kebutuhan stakeholders di segala bidang dalam rangka mencapai pengakuan internasional.
- Memberikan jaminan partisipasi aktif dalam membangun sumber daya manusia yang berkualitas dan mampu beradaptasi dalam berbagai lingkungan pekerjaan serta sumbangsih dalam implementasi penelitian yang bermanfaat b agi masyarakat luas.
Misi, Visi dan Tujuan Teknik Informatika
- Visi STMIK Raharja
- Misi STMIK Raharja
- Keunggulan Dalam Manajemen Universitas
- Keunggulan Dalam Pendidikan
- Keunggulan Dalam Penelitian
- Keunggulan Dalam Pengabdian Masyarakat
- Tujuan STMIK Raharja
- Memberikan layanan yang profesional serta menghasilkan lulusan yang sesuai dengan harapan Stakeholder
- Menciptakan suasana akademik yang kondusif dengan orientasi Student Centered Learning sehingga menghasilkan lulusan yang profesional dan mampu berkarya di bidang Software Engineering dan Multimedia Audio Visual and Broadcasting
- Menghasilkan karya-karya yang diakui baik secara nasional maupun internasional melalui penelitian di bidang Teknologi Informasi khususnya Software Engineering dan Multimedia Audio Visual and Broadcasting
- Menghasilkan lulusan yang mampu mengamalkan keahliannya di bidang Software Engineering dan Multimedia Audio Visual and Broadcasting yang bermanfaat bagi masyarakat serta mampu menciptakan lapangan pekerjaan.
- Kompetensi Lulusan

Tata Laksana Sistem Yang Berjalan
Prosedur Sistem Yang Berjalan
Flowchart Analisa Sistem Yang Berjalan

Analisa Sistem Yang Berjalan
Analisa Sistem Pada SWOT

Analisa Sistem Yang Akan Dikembangkan
Identifikasi Masukan Data
- Nama Masukan: File dokumen pdf
- Fungsi: sebagai media yang menampilakn originality sebuah dokumen dan menghasilkan prosentase kemiripan kata penulisannya.
- Sumber: Pengguna
- Media: Aplikasi Web
- Frekuensi: Setiap user melakukan upload file dokumen pdf untuk di scanning
- Format: Tampilan Web
- Keterangan : Hasil analisa laporan originality
Identifikasi Proses Data
- Nama modul: Permintaan input file dokumen pdf.
- Masukan: File dokumen pdf.
- Keluaran: Report perbandingan analisa kemiripan 2 file dokumen pdf.
- Rigkasan proses: Proses ini akan menghasilkan report detail hasil analisa perbandingan originality dan prosentase file dokumen pdf yang di upload oleh user.
Identifikasi Keluaran Data
- Nama keluaran: Permintaan Hasil analisa perbandingan dokumen pdf
- Fungsi: Menampilkan Detail Analisa Laporan Originality Dokumen.
- Media: Aplikasi web
- Distribusi: Web
Analisa Sumber Pengetahuan
Konfigurasi Sistem Yang Berjalan
Spesifikasi Hardware
- Processor: Intel(R) Core(TM) i3-2310M
- Monitor: SVGA 15”
- Mouse: Optical
- Keyboard: PS/2
- RAM: 2 GB
- Harddisk : 500 GB”
- Printer: Canon
Spesifikasi Software
- Microsoft Office 2007
- Adobe Dreamweaver
- Notepad++
- Google Chrome
- Adobe Photoshop
- Edraw Max
- Xampp
Hak Akses (Brainware)
- Stakeholder
- Admin
Permasalahan Yang Dihadapi dan Alternatif PemecahanMasalah
Permasalahan Yang Dihadapi
- Membandingkan dokumen untuk pengukuran prosentase kemiripan pada penulisan ilmiah yang dilakukan oleh kalangan akademis masih jarang digunakan sehingga untuk penggunaannya masih sulit.
- Dengan banyaknya jenis file dokumen yang digunakan dalam analisa sistem untuk membandingkan dokumen maka dibatasi jenis file dokumennya yaitu pdf sehingga dapat mengetahui tingkat kemiripannya.
Alternatif PemecahanMasalah
- Merancang sistem dengan menggunakan flowchart sehingga sistem dalam memberikan detail laporan analisa originality dokumen yang berjalan lebih optimal.
- Menyediakan suatu sistem pembanding dokumen untuk mengetahui prosentase kemiripan tulisannya dengan menggunakan akses internet hanya dengan mengupload file dokumen sehingga menghasilkan laporan analisa originality dokumen dengan cepat dan akurat serta meningkatkan kinerja yang optimal.
- Menyediakan aplikasi database yang terelasi dengan tabel-tabel sistem analisa sehingga diperlukan sebuah program yang dapat menunjang dan mempermudah kegiatan tanpa merubah prosedur yang berjalan.
User Requirement
Elisitasi Tahap I

Elisitasi Tahap II


Elisitasi Tahap III


Final Draft Elisitasi

BAB IV
Perancangan Database atau Basis Data
Normalisasi
- Unnormalized
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)




Spesifikasi Basis Data
- Tabel Informasi
- Tabel Analisa Dokumen


Perancangan Flowchart Sistem yang di usulkan
Perancangan Prosedural
- Flowchart proses sistem
- Flowchart prepocessing
- Flowchart Read Dokument
- Flowchart Get Info Dokument
- Flowchart Analyze Result Paper
- Flowchart prosentase and level indikator
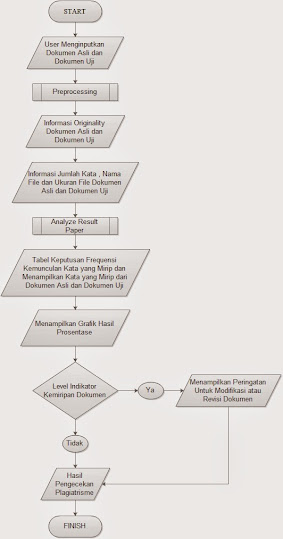


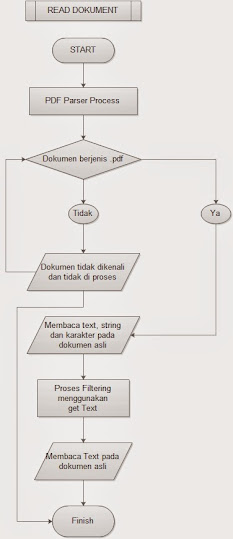





Rancangan Program

- Nama program: Menu Utama.
- Nama program: Home.
- Nama program: Scanning File.
- Pada “Menu Utama” lalu pilih menu “choose file” pilih file dokumen yang akan di scanning dengan type file pdf.
- Klik button upload untuk memproses scanning dan menghasilkan original text, jumlah kata, frequensi kemiripan kata, menampilkan kata yang mirip, grafik prosentase dan level indikatornya.
- Nama program: Report.
- Nama program: About.
Rancangan Prototype
Interface Pembuatan Sistem
- Prototype Halaman Awal (HOME)
- Prototype halaman scanning file
- Prototype Halaman Report -> History
- Prototype Halaman About -> About Application
- Prototype Halaman About -> About Me





Konfigurasi Sistem Usulan
Spesifikasi Hardware
- Processor: Intel(R) Core(TM) i3-2310M
- Monitor: SVGA 15”
- Mouse: Optical
- Keyboard: PS/2
- RAM: 2 GB
- Harddisk: 500 GB”
- Printer: Canon
Aplikasi Yang Digunakan
- Sistem Operasi “Windows 7 Ultimate”
- Microsoft Office 2007
- Adobe Dreamweaver
- Notepad++
- Xampp
- Google Chrome
- Adobe Photoshop
- Edraw Max
- MS. Visio
Hak Akses
- Stakeholder
- Kepala Jurusan Teknik Informatika-S1
- Mahasiswa Jurusan Teknik Informatika – S1
Testing
Metode Implementasi
Pengujian Blackbox

Evaluasi
Schedule Implementasi

Estimasi Biaya

BAB V
Kesimpulan
Kesimpulan Terhadap Rumusan Masalah
- Cara membandingkan dokumen untuk mengukur prosentase tingkat kemiripan penulisan dapat menggunakan sistem dengan fasilitas scanning file untuk menghasilkan analisa prosentase kemiripan antar dokumen.
- Dengan adanya sistem yang menghasilkan prosentase tingkat kemiripan bisa digunakan dengan optimal untuk menentukan seberapa besar kemiripan dokumen, dan dapat mengetahui status tingkat kemiripannya serta mampu memberikan pesan untuk modikasi jika tingkat kemiripan yang tinggi.
- Dengan adanya sistem yang mampu menghasilkan analisa prosentase tingkat kemiripan pada sebuah dokumen mampu mengurangi tindakan plagiatrisme pada kalangan akademik karena sebelum melakukan penerbitan ataupun publish akan di cek terlebih dahulu keaslian atau Originality sebuah dokumen dengan dokumen pembandingnya.
Kesimpulan Terhadap Tujuan dan Manfaat Penelitian
- Aplikasi dapat meminimalkan atau mengurangi tindakan plagiat pada sebuah karya ilmiah dengan adanya checker similarity pada Jurusan Teknik Informatika.
- Dapat melindungi Hak Cipta kepemilikan dari sebuah dokumen karya ilmiah yang dipublikasikan.
- Mencoba membantu para dosen pengajar dan mahasiswa dalam hal pemeriksaan dokumen karya ilmiah pada Teknik Informatika di Perguruan Tinggi Raharja.
Kesimpulan terhadap metode penelitian
- Penulis perlu menganalisa sistem yang berjalan, dengan cara mengadakan pengamatan langsung atau observasi.
- Untuk mendapatkan informasi yang lebih jelas, penulis melakukan wawancara dengan stakeholder mengenai apa saja yang diinginkan dalam pengembangan sistem yang akan digunakan.
- Penulis juga melakukan pengumpulan data dengan cara studi pustaka yaitu dengan membaca buku, jurnal, dan artikel yang sesuai dengan pembahasan.
Saran
- Untuk mengembangkan aplikasi menjadi lebih baik kedepannya dapat menghasilkan hasil similarity yang lebih akurat dari yang ada untuk membuat hasil analisa prosentase tingkat kemiripan yang lebih baik dalam membandingkan.
- Untuk mempercepat proses eksekusi dan membuat keamanan untuk sistem yang digunakan sehingga mempunyai daya akses yang cepat dan aman.
- Untuk memberikan kenyaman kepada User (pengguna) selama pemakaian aplikasi dan memberikan fasilitas tambahan pada sistem agar menjadi aplikasi sistem yang sempurna.
DAFTAR PUSTAKA
- ↑ 1,0 1,1 1,2 1,3 1,4 Nugroho, Andi. 2011. Algoritma dan Struktur Data Menggunakan Bahasa Pemrograman C++. Yogyakarta: Penerbit ANDI.
- ↑ Rahma, Rana. 2013. Algoritma dan Pemrograman. Diakses tanggal 16 Mei 2014. http://ranaardila.com/2013/03/algoritma-dan-pemrograman.html
- ↑ Kusumadewi, Sri. 2013. Artificial Intelligence (Teknik dan Aplikasinya) Edisi ke-1. Yogyakarta:Graha Ilmu.
- ↑ Kusumadewi, Sri. 2013. Artificial Intelligence (Teknik dan Aplikasinya) Edisi ke-1. Yogyakarta:Graha Ilmu.
- ↑ Wuryandari, Maharani Dessy, Afrianto, Irawan. 2012. Perbandingan Metode Jaringan Syaraf Tiruan Backpropagation Dan Learning Vector Quantization Pada Pengenalan Wajah. Jurnal KOMPUTA Edisi.I Vol.1 Maret 2012.
- ↑ Efraim Turban, Jay E.Aronson, Ting Peng Liang. 2010. Decision Support Systems and Intelligent System (Sistem Pendudukung Keputusan dan Sistem Cerdas), Edisi 7, Jilid 2, Yogyakarta: Andi Offset.
- ↑ Achmad, Balza. 2012. Diktat Kecerdasan Buatan. Yogyakarta: Universitas Gajah Mada.
- ↑ Adelia, Jimmy Setiawan. 2011. Implementasi Customer Relationship Management (CRM) pada Sistem Reservasi Hotel berbasisi Website dan Desktop. Bandung: Universitas Kristen Maranatha. Vol. 6, No. 2, September 2011:113-126.
- ↑ Sulindawati, dan Muhammad Fathoni. 2010. PengantarAnalisa Perancangan “Sistem”. Medan: STMIK Triguna Dharma. Vol. 9, No. 2, Agustus 2010.
- ↑ Supriyono. 2013. Manajemen Jurnal Cetak, Elektronik dan bahan khusus Di Perpustakaan UGM. Yogyakarta: Universitas Gajah Mada.
- ↑ 11,0 11,1 11,2 Rangkuti. Freddy. 2011. Teknik Menyusun Strategi Korporat Yang Efektif Plus Cara Mengelola Kinerja Dan Risiko, SWOT Balanced Scorecard. Jakarta: Gramedia Pustaka Utama.
- ↑ Yusmini, dkk. 2011. Analisis Finansial Kud Mandiri Mojopahit Jaya Desa Sari Galuh Kecamatan Tapung Raya Kabupaten Kampar. Pekanbaru: Universitas Riau.
- ↑ 13,0 13,1 13,2 Prasetio. Adhi. 2012. Buku Pintar Pemrograman Web. Jakarta : Mediakita.
- ↑ Mustakini. Jogiyanto Hartono. 2009. Sistem Teknologi Informasi. Yogyakarta: Andi.
- ↑ 15,0 15,1 15,2 Anhar. 2010. Panduan Menguasai PHP & MySQL Secara Otodidak. Jakarta: Mediakita.
- ↑ 16,0 16,1 Oktavian. Diar Puji. 2010. Menjadi Programmer Jempolan Menggunakan PHP. Yogyakarta: Mediakom.
- ↑ 17,0 17,1 17,2 17,3 17,4 17,5 17,6 Arief. M. Rudyanto. 2011. Pemrograman Web Dinamis Menggunakan PHP & MySQL. Yogyakarta: Andi.
- ↑ 18,0 18,1 Madcoms. 2010. Kupas Tuntas Adobe Dreamweaver CS5 Dengan Pemrograman PHP & MySQL. Yogyakarta: Andi.
- ↑ 19,0 19,1 Wardana. 2010. Menjadi Master PHP Dengan Framework Codeigniter. Jakarta: Elex Media Komputindo.
- ↑ 20,0 20,1 20,2 20,3 Nugroho, Bondan Dwi, Imam Azhari. Sistem Informasi Inventori FADEGORETAS!!™ Berbasis Barcode. Yogyakarta: Universitas Ahmad Dahlan. Vol. 1, No. 2, September 2009.
- ↑ Murad. Dina Fitria, Kusniawati. Nia, Asyanto. Agus. 2013. Aplikasi Intelligence Website Untuk Penunjang Laporan PAUD Pada Himpaudi Kota Tangerang. Jurnal CCIT. Tangerang: Perguruan Tinggi Raharja. Vol. 7, No. 1, September 2013.
- ↑ Simarmata. Janner. 2010. Rekayasa Web. Yogyakarta: Andi.
- ↑ Sarosa. 2009. Dasar Perancangan Dan Implementasi Database Relasional. Yogyakarta: Andi.
- ↑ 24,0 24,1 24,2 24,3 24,4 Rizky. Soetam. 2011. Konsep Dasar Rekayasa Perangkat Lunak. Jakarta: Prestasi Pustaka.
- ↑ Ardini Ridhatillah. 2013. Dealing with Plagiarism in the Information System Research Community: A Look at Factors that Drive Plagiarism and Ways to Address Them, MIS Quarterly; Vol. 27, No. 4, p. 511-532.
- ↑ 26,0 26,1 26,2 Srininang Hadjarati, 2013. Penerapan String Matching Pada Aplikasi E-Arsip Berbasis Web Di Jurusan Teknik Elektro Fakultas Teknik Universitas Negeri Gorontalo. Gorontalo: Universitas Negeri Gorontalo.
- ↑ 27,0 27,1 Schleimer, Saul, Daniel S. Wilkerson, dan Alex Aiken, “Rabin Karp: Local Algorithms for Document Fingerprinting”, Diakses tanggal 26 05 Januari 2014. http://www.theory.stanford.edu/~aiken/publications/papers/sigmod03.pdf.
- ↑ Kurniawati, Ana, Wicaksana, I Wayan Simri. 2012. Perbandingan Pendekatan Deteksi Plagiarism Dokumen Dalam Bahasa Inggris. Fakultas Ilmu Komputer dan Teknologi Informasi, Universitas Gunadarma.
- ↑ Junaidi, Fifit Alfiah, dkk. 2014. Collaborative Methode Model Dalam Membandingkan Dokumen Untuk Mengukur Prosentase Kemiripan. ISSN: 2355-‘941 KNSI 2014, Februari 2014.
- ↑ 30,0 30,1 30,2 30,3 Nugroho, Eko. 2011. Perancangan Sistem Deteksi Plagiarisme Dokumen Teks Dengan Menggunakan Algoritma Rabin-Karp. Malang : Universitas Brawijaya.
- ↑ Stoimen. 2012. computer-algorithms-rabin-karp-string-searching. Diakses tanggal 24 November 2014 http://www.stoimen.com/blog/2012/04/02/computer-algorithms-rabin-karp-string-searching/
- ↑ Pyriana, Dewi Rokhmah, Suprapto, Suharsono,Aswin. 2013. Program Aplikasi Editor Kata Bahasa Indonesia Menggunakan Metode Approximate String Matching Dengan Algoritma Levenshtein Distance Berbasis Java.Malang : Universitas Brawijaya.
- ↑ 33,0 33,1 Hermawan. Asep. 2009. Penelitian Bisnis. Jakarta: Grasindo.
- ↑ Semiawan. Conny. R. 2010. Metode Penelitian Kualitatif. Jakarta: Grasindo.
- ↑ Yuniarti. Evi, dkk. 2012. Kinerja Laporan Keuangan Untuk Pengambilan Keputusan Pemberian Kredit Modal Kerja. Lampung: Politeknik Negeri Lampung.
- ↑ 36,0 36,1 Guritno. Suryo, Sudaryono, dan R. Untung. 2011. Theory and Application of IT Research Metodologi Penelitian Teknologi Informasi. Yogyakarta.